# 浏览器共享渲染进程

我们通常认为 Chrome 会为每个页面分配一个渲染进程,但实际情况要复杂得多。我们知道,进程之间是相互隔离的,如果每个页面都是运行在自己页面单独的渲染进程中的话,如果页面崩溃或卡顿时,影响的也应该只是当前页面。但实际情况是,有时候一个页面的问题可以导致浏览器中其他页面的崩溃,这种情况是因为在特定情况下这些页面共享了同一个渲染进程,这个渲染进程崩溃后,相关的页面都受到了影响。
那么什么情况下页面之间会共享渲染进程呢?要弄清这个问题,我们需要从 Site 的相关概念开始。
# Same Site
Same Site 直译过来就是同站(或者同一站点),它和 Same Origin(同源) 是不同的。Same Origin 要求协议、域名、端口号三者必须完全一致,Same Site 的要求就要宽松一些,主要是根据注册域名 (即有效顶级域名的下一级域名 eTLD+1) 是否一致来判断(如下图)。

- TLD:
Top-Level-Domain,顶级域名,TLD有个记录的表,叫 Root Zone DataBase (opens new window), - eTLD:
effective Top-Level Domain, 有效顶级域名,记录在Mozilla维护的公共后缀表 Pulic Suffix List (opens new window)中。eTLD的出现主要是为了解决.com.cn,.com.hk, .co.jp这种看起来像是一级域名的但其实需要作为顶级域名存在的场景。
在上面的例子中,eTLD 为 .com, eTLD+1 为 example.com。因此,http://www.example.com/ 和 test.example.com 为同站域名。但是像 github 这种提供子域名给用户建站的服务,为了保证不同用户间的站点隔离,会将一级域名 github.io 添加到 eTLD 的列表中去,这样 https://baidu.github.io和 https://blog.github.io 就会被判断为不同的站点。
# Schemeful Same Site
Schemeful Same Site (opens new window) 是在 Same Site 的基础上增加了协议的判断。但是这里的判断也并不是完全的不等判断,可以理解是否有 SSL 的区别。例如 http:// 和 https:// 跨站,但 wss:// 和 https:// 则是同站,ws:// 和 http:// 也算是同站。
版本兼容性:Schemeful Same Site 是 chrome 在 86 版本新增的配置,默认是关闭状态,从 88 版本开始灰度为默认开启状态。在这些版本可以通过在浏览器中输入 chrome://flags/#schemeful-same-site 来设置开启或关闭状态。不过从 89 版本开始, Schemeful Same Site 已全部默认为打开状态。
综上,如果对应的浏览器版本中 schemeful-same-site 为打开状态,则 scheme 和 eTLD+1 一致的站点会认为是同站,如果 schemeful-same-site 是关闭的,则只判断 eTLD+1 是否一致即可。
# Site Instance
Site Instance 是一组相关联(connected)的 Site。如果在页面的 JS 代码中获取页面的引用(window.opener),我们则认为页面是相关联的。两个页面为 Same Site 并满足下面的条件(本质是页面间通过 opener 建立连接),就是同一个 Site Instance:
- 用户通过
a标签的href打开的新页面(rel=”opener”和target=”\_blank”必须同时出现) - 通过
JS代码打开的新页面(如window.open)
# Process Models
了解了 Site 和 Site Instance 的概念之后,我们还需要再了解下浏览器的 Process Model(进程模式),因为不同的进程模式下,浏览器分配渲染进程的行为是不一样的。
Chromium提供了四种进程模式(Process Models 参考文档 (opens new window)),不同的进程模式会对 tab 的进程做不同的处理:
Process-per-site-instance: 这个是Chromium的默认模式,同一个site-instance使用一个进程Process-per-site: 同一个site使用一个进程Process-per-tab: 一个tab使用一个进程Single process: 所有tab共用一个进程
假设我们现在有两个页面,地址分别为 https://a.exapmle.com和 https://b.example.com
Process-per-tab 模式下 a.example.com 和 b.exapmle.com 会使用不同的进程
Single process 则是两者共用一个进程
如果使用 Process-per-site 模式,两个页面因为是 Same Site,所以两个页面无论是通过浏览器直接打开的 tab,还是通过 a.example.com 的 JS 打开了 b.exapmle.com,两者都会共用一个进程
Process-per-site-instance 是最重要的,因为这个是 Chrome 默认使用的模式,也就是几乎所有的用户都在用的模式。当你打开一个 tab 访问 a.example.com,然后再打开一个 tab 访问 b.example.com,这两个页面就会使用不同的进程。
如果是通过 a.example.com 的 JS 打开的 b.exapmle.com,这两个 tab 会使用同一个进程。如果两个页面共用了一个进程,我们可以在 Chrome 中的任务管理器中看到,两者共用的是同一个 processId
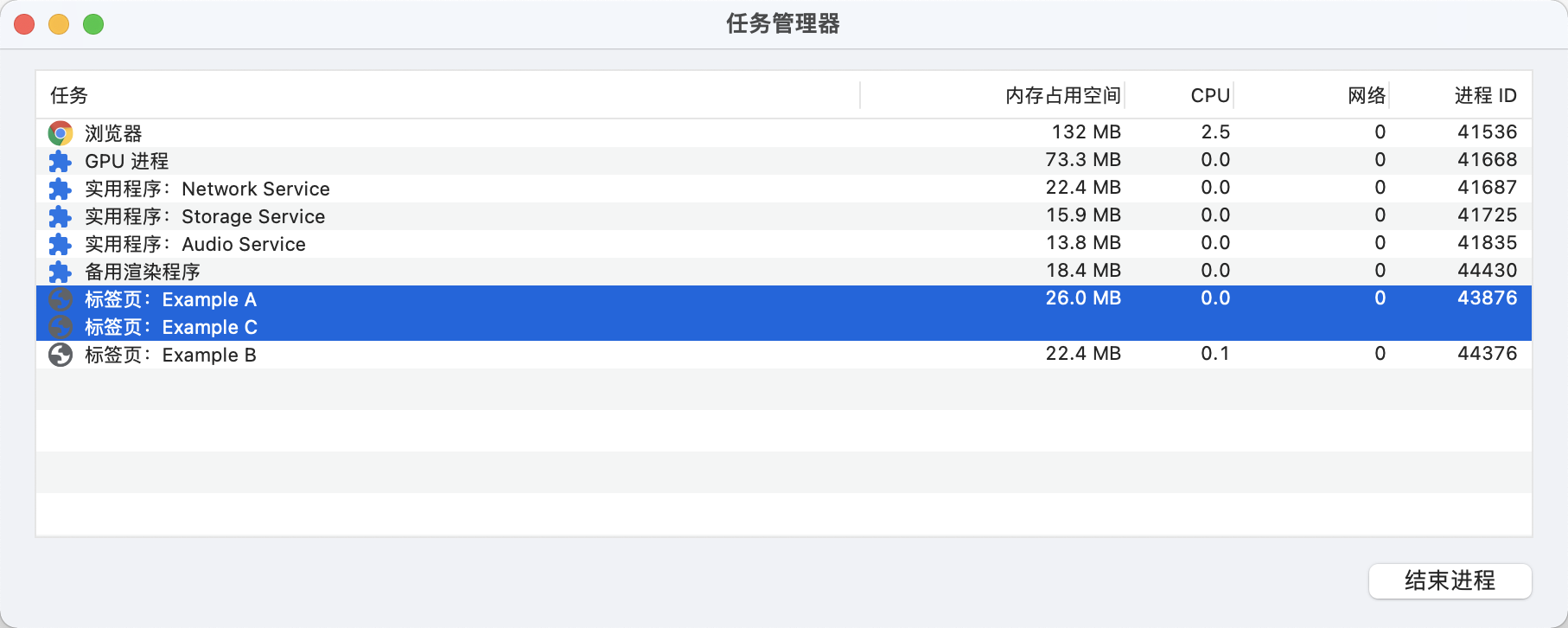
从上图中我们可以看到,a.example.com 和 b.example.com 两者使用了同一个 processId 43876。
如果要修改 Chrome 的进程模式,可以在启动时添加对应的模式的参数,比如我们想要使用 Process-per-site 模式(以Mac为例):
open -n /Applications/Google\ Chrome.app/ --args --process-per-site
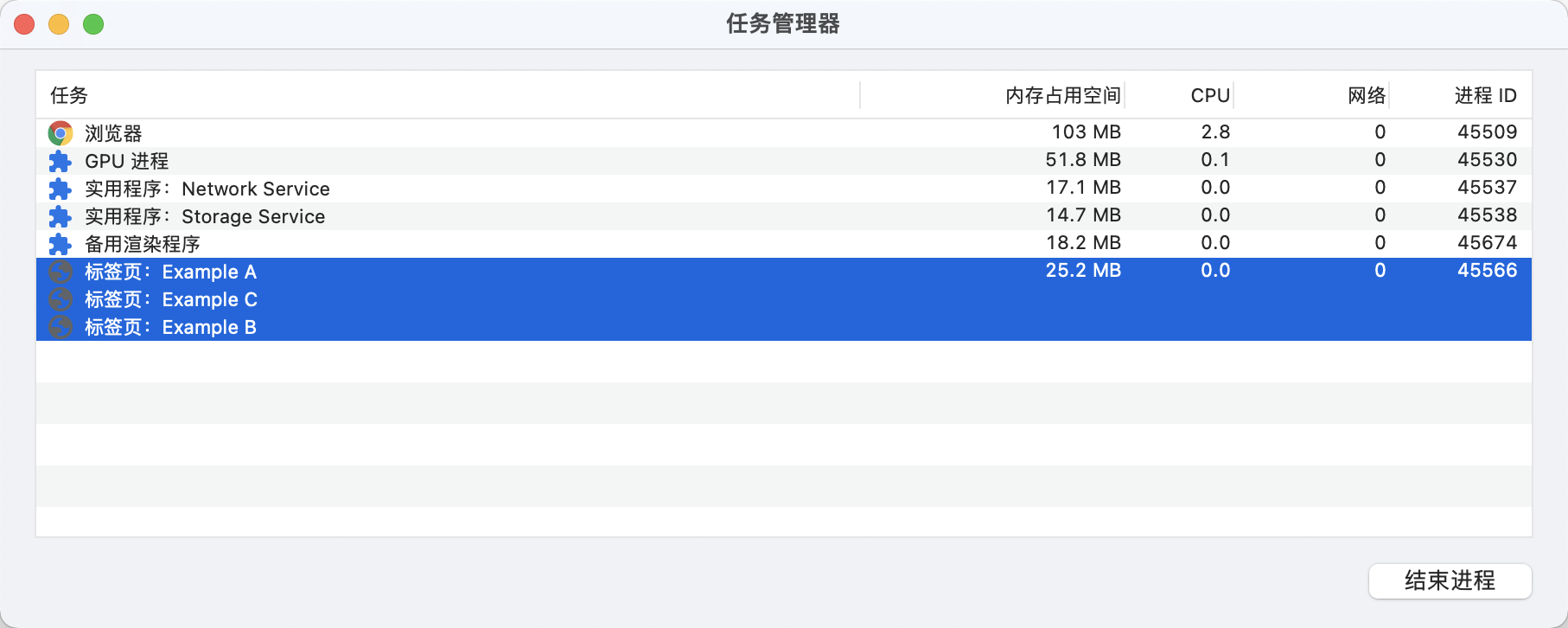
修改为 process-per-site 模式之后,我们可以看到,三个页面共用的同一个 processId 45566。
对比上面的两张图,我们可以看到,只有 a、c 两个页面共享进程时, 内存占用为 26.0 + 22.4 = 48.4MB,三个页面共享进程时内存占用为 25.2MB,也就是说合并渲染进程可以有效减少内存占用。选择 Process-per-site-instance 作为 chrome 的默认值是因为 Process-per-site-instance 兼顾了性能与易用性,和 Process-per-tab 相比,可以避免开很多进程,占用更少的内存;和 Process-per-site 相比,能够更好的隔离相同域名下毫无关联的 tab,更加安全。
除了上面四种模式外,Chrome 还有更严格的模式 strict-origin-isolation,这种模式将严格按照 Same Origin(同源)的标准来合并进程。目前这种模式还在实验阶段,可以通过在浏览器中输入 chrome://flags/#strict-origin-isolation 来开启。
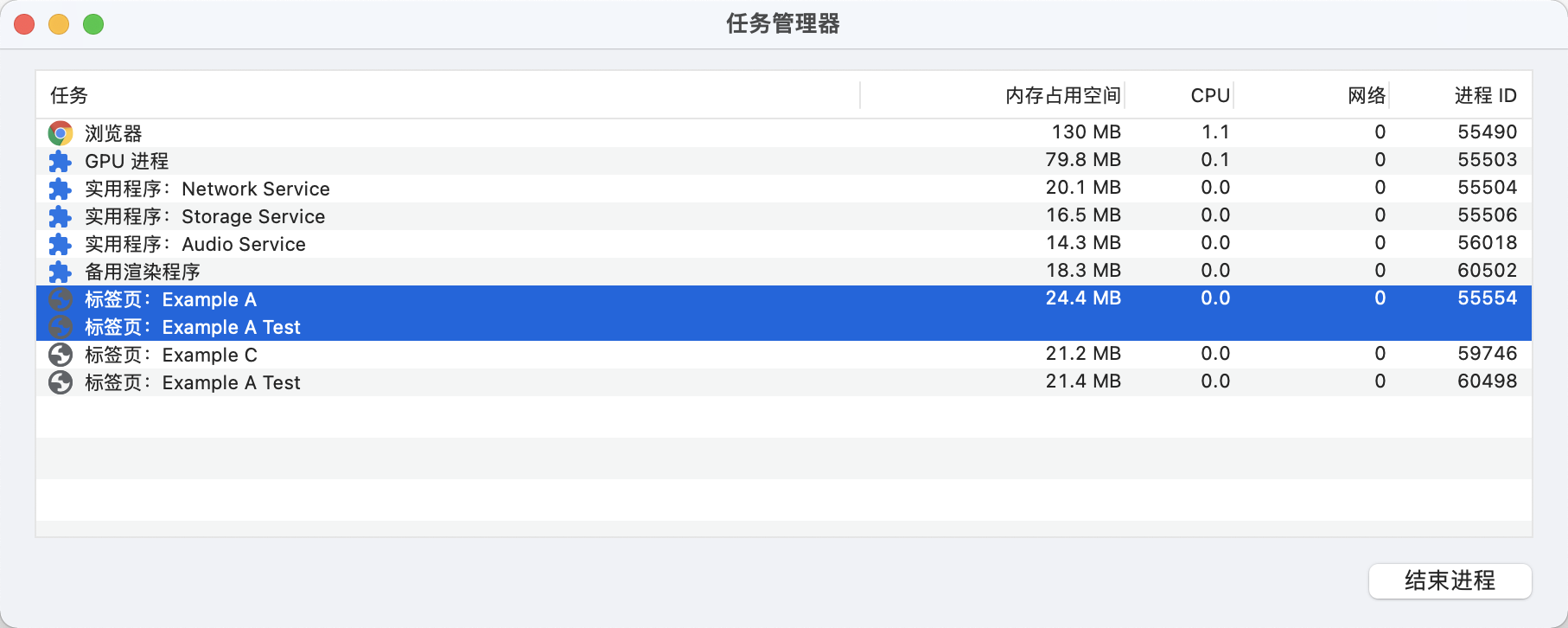
开启了 strict-origin-isolation 之后,原来可以共享进程的 a.example.com 和 c.example.com 在这里因为不符合同源策略,被划分到两个进程里了,上图中的 Example A Test,地址为 https://a.example.com/test.html,符合同源策略,一个是直接打开的,一个是通过 a.example.com 打开的,通过 a.example.com 打开的页面和 a.example.com 共用了一个进程,而直接打开的则是单独一个进程。上面的结果是 Process-per-site-instance 和 strict-origin-isolation 共同作用的结果(存疑,需要文档验证)。
另外,如果 Chrome 的内存快被耗尽,Chrome 会合并一些页面的进程。
# 共享进程作用
多个页面共享进程,优点是显著减少内存的使用,同时我们可以通过opener 获取页面的window 对象,更方便的使用PostMessage等;
但多个页面公用一个渲染进程,也就意味着多个页面共用同一个主线程,所有页面的任务都是在同一个主线程上执行,这些任务包括渲染流程、JS执行、用户交互的事件的响应等等。如果一个标签页里面执行一个死循环,那就意味着主线程会一直被占用,这样就导致了其它的页面无法使用该主线程,从而让所有页面都失去响应。
下面我们看一个示例,这个示例展示了页面共享渲染进程时主线程被占用并且影响其他页面渲染的情况。
Top Window(top.html) 代码:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Top Window</title>
</head>
<body>
<script>
function longrunning() {
for (let i = 0; i < 2000000000; i++);
}
let t0
let t1
const elapsedTime = () => {
if (!t0) {
t0 = performance.now()
t1 = t0
} else {
t1 = performance.now()
}
return ((t1 - t0) / 1000).toFixed(2)
}
window.parentLogger = (str) => {
console.log("[%s] TOP: %s", elapsedTime(), str)
}
window.childLogger = (str) => {
console.log("[%s] CHILD: %s", elapsedTime(), str)
}
parentLogger('before opening popup')
const popup = window.open('child.html')
if (popup) {
parentLogger(`after popup opened, popup window url: ${popup.location.href}`)
}
parentLogger('starting long synchronous process. This will prevent loading and parsing of popup window')
longrunning();
parentLogger('finished long synchronous process.')
parentLogger('adding 1s timeout.')
setTimeout(function () {
parentLogger('timed out')
}, 1000)
</script>
</body>
</html>
Child Window(child.html) 代码:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Child Window</title>
</head>
<body>
<script>
function longrunning(){
for(let i=0;i<2000000000;i++);
}
window.addEventListener('DOMContentLoaded', e => window.opener.childLogger(`popup initial html loaded, popup window url: ${window.location.href}`))
window.opener.childLogger('starting long synchronous process inside popup window. This will prevent the event loop in top window')
longrunning()
window.opener.childLogger('finished long synchronous process inside popup window.')
</script>
</body>
</html>
上面的代码中,Top Window 打开了 Child Window后执行了一个很长的 JS 循环 longrunning,之后又执行了一次 setTimeout 事件。而 Child Window 监听了 DOMContentLoaded 事件,之后也执行了一个很长的 JS 循环 longrunning。我们来看下执行结果(图中中括号中的数字为执行时间):
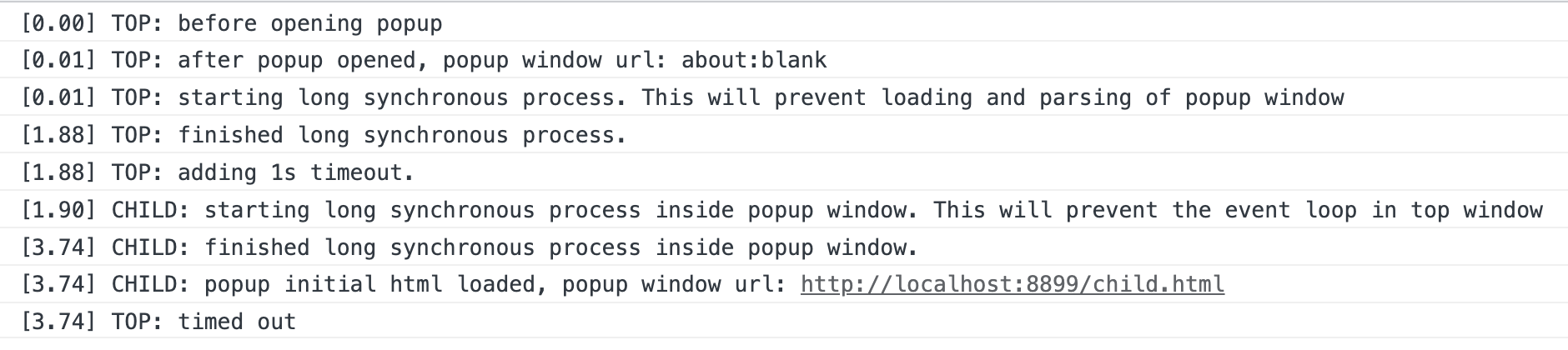
下面是详细的步骤:
- 打开
Child Window的操作是同步的,但是Child Window中内容的加载是异步的,所以我们拿得到的Child Window的href为about:blank,实际 URL 的获取会延迟到当前当前脚本执行完成才能开始; - 接下来我们在
Top Window中执行了一个很长的同步任务,这个同步任务阻塞了事件循环和后续的所有 JS 事件,此时Child Window的内容依然没有被加载; - 之后我们增加了一个
timeout事件,此时Top Window的 JS 执行完毕,Child Window可以执行进行内容的加载; Child Window开始加载内容并执行 JS,同样的,Child Window也执行了一个很长的同步任务,这意味着在这段时间内,Top Window的setTimeout事件依然不能执行;Child Window的DOMContentLoaded事件被触发,此时Child Window的 JS 执行完毕;Top Window的 1秒后的setTimeout回调在接近 2 秒之后才被执行
从上面的例子可以看到共享渲染进程的两个页面是如何互相影响的,因此,我们在不需要用 JS 访问父页面时,要注意页面的打开方式,对应到 Chrome 默认的 Process-per-site-instance 模式,我们就是要取消页面间的关联关系:
- 通过
href打开的新页面时,如果target=”\_blank”时,要注意rel不能为opener(rel 默认为noopener,也可以设置ref=“noopener”) - 使用
window.open方法时,需要在第三个参数加上noopener:window.open(url, windowName, ‘noopener’)
# 渲染性能优化
在介绍优化页面的具体方法之前,我们先来简单了解下 RAIL 模型。RAIL 是一种以用户为中心的性能模型,它提供了一种考虑性能的结构。RAIL 代表 Web 应用生命周期的四个不同方面:响应(Response)、动画(Animation)、空闲(Idel)和加载(Load)。
性能目标是根据所处的 Web 生命周期的阶段以及用户如何感知延迟的用户体验研究来定义的。RAIL 模型将用户作为性能工作的关键点,下表是 RAIL 性能模型中用户对性能延迟的看法(使用RAIL模型衡量性能 (opens new window)):
| 时间 | 说明 |
|---|---|
| 0 至 16 毫秒 | 用户非常关注轨迹运动,他们不喜欢不流畅的动画。如果每秒渲染 60 个新帧,他们就认为动画很流畅。也就是说,每一帧只有 16 毫秒时间,这包括浏览器将新帧绘制到屏幕所需的时间,因而应用约有 10 毫秒的时间来生成一个帧。 |
| 0 到 100 毫秒 | 在此时间窗口内响应用户操作会让用户觉得结果是即时呈现的。如果时间更长,操作与用户反应之间的联系就会中断。 |
| 100 到 1000 毫秒 | 在此时间窗口内,用户会觉得任务进展基本上是自然连续的。对 Web 上的大多数用户来说,加载页面或更改视图是一项任务。 |
| 1000 毫秒或更长 | 超过 1000 毫秒(1 秒),用户的注意力就会从正在执行的任务上转移。 |
| 10000 毫秒或更长 | 超过 10000 毫秒(10 秒),用户会感到失望,并且可能放弃任务。他们以后可能会回来,也可能不会再回来。 |
基于上表,RAIL 模型中各个阶段的目标如下:
- 响应:在 50 毫秒内处理事件。从上表中我们知道,100 毫秒以内的反馈对用户来说是连续没有延迟的,那为什么这里要求在50毫秒内处理呢?这是因为除了要处理用户输入(切换表单、点击按钮等)外,通常还要利用空余时间来执行其他工作。如果以 100 毫秒的区块来执行其他工作,那么用户输入到达之后,最多会排队等待 100 毫秒,再加上用户输入时还要进行处理(浏览器线程中通信),这样加起来就超过了 100 毫秒。考虑到这一点,RAIL 模型认为 50 毫秒内响应用户操作才是安全的。
- 动画:在 10 毫秒内生成一帧。从技术上来讲,每帧的最大预算为 16 毫秒(1000 毫秒/每秒 60 帧≈16 毫秒),但是,浏览器需要大约 6 毫秒来渲染一帧,因此,准则为每帧 10 毫秒。
- 空闲:最大限度增加空闲时间,目的是为了提高页面在 50 毫秒内响应用户输入的几率。
- 加载:在 5 秒内交付内容并实现可交互。当页面加载缓慢时,用户注意力会分散,他们会认为任务已中断。加载速度快的网站具有更长的平均会话时间、更低的跳出率和更高的广告可见性。对于首次加载,目标是 5 秒或更短的时间内实现可交互,对于后续加载,目标是 2 秒内加载页面。
在这个模型中, 50 毫秒的响应时间是一个非常重要的指标,超过 50ms 的任务就是长任务,因此,优化页面时,我们必须要减少长任务,也就是说,减少 JavaScript 脚本的执行时间。
# 减少脚本执行时间
我们知道,如果一个任务长时间占用主线程(Main),页面渲染及用户输入等得不到响应,容易造成页面假死或者卡顿的现象。
有长任务时,一个比较简单粗暴的做法就是可以使用 setTimeout 等方法,将其放到任务队列,通过异步的方式执行。但这种方式并没有解决根本问题,即使长任务没有阻塞当下,但 JavaScript 脚本执行时依然会长时间占用主线程。目前减少 JavaScript 的执行时间有两种方案,一种是使用 Web Workers,另一种是使用时间切片(Time Slicing)。
我们先来看下长任务的示例。
在上文介绍共享渲染进程优缺点的小节中,我们提供的示例中有个 longrunning 的方法,这里依然以此为示例。在 Chrome 的 Performance 中,长任务会被标记为红色,点击对应的位置,我们可以在 Main 中看到这个任务的执行时间,如下图:
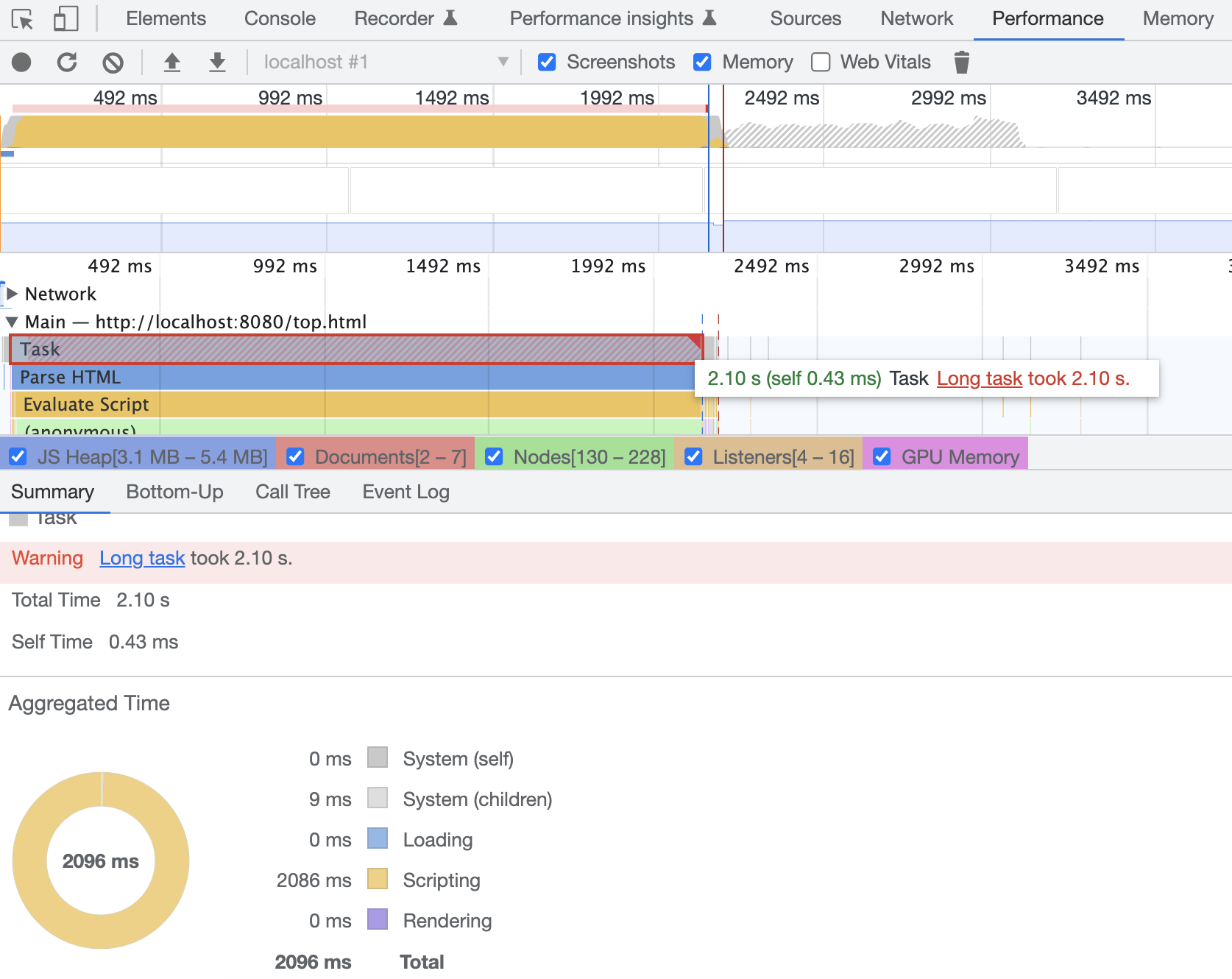
上图可以看到,执行时间为 2.10 秒,远超了我们上文提到的 50 毫秒。即使我们不能保证所有任务都在 50 毫秒内执行完毕,也要尽可能减少对主进程的占用时间。
# 使用Workers
我们可以把 Web Workers 当作主线程之外的一个线程,在 Web Workers 中可以执行 JavaScript 脚本。需要注意的是, Web Workers 中没有 DOM、CSSOM 环境,因此适合处理一些和 DOM、CSSOM 无关的任务(Web Workers API (opens new window))。
这里列举下 Web Workers 的限制条件:
同域限制 子线程加载的脚本文件,必须与主线程的脚本文件在同一个域
DOM限制 子线程无法读取网页的DOM对象,即
document、window、parent这些对象,子线程都无法得到 (但是,navigator对象和location对象可以获得 )脚本限制 子线程无法读取网页的全局变量和函数,也不能执行
alert和confirm方法,不过可以执行setInterval和setTimeout,以及使用XMLHttpRequest对象发出AJAX请求文件限制 子线程无法读取本地文件,即子线程无法打开本机的文件系统(
file://),它所加载的脚本,必须来自网络
我们首先创建一个 worker.js,在这里执行 longrunning 中的操作,在 top.html 中创建 worker 子线程,并且与主线程进行通信
// workers.js
postMessage('worker start');
for (let i = 0; i < 2000000000; i++) {};
postMessage('worker end');
// top.html
let worker = new Worker('./worker.js');
worker.onmessage = (event) => {
parentLogger(event.data);
}
使用 Web Workers 之后,Main 中没有了长任务的提示,我们可以在 Workers 中看到执行的任务:

# 使用时间切片
时间切片(Time Slicing)是一项使用得比较广的技术方案,它的核心思想是:如果任务不能在50毫秒内执行完,那么为了不阻塞主线程,这个任务应该让出主线程的控制权,使浏览器可以处理其他任务。时间切片可以理解为是一种技术手段,就是将长任务分割为一个个执行时间很短的任务,然后再一个个地执行。
我们可以使用定时器来实现,比如,我们将本应执行100毫秒的任务拆分成两个小任务。
btn.onclick = function () {
someThing(); // 执行了50毫秒
setTimeout(function () {
otherThing(); // 执行了50毫秒
});
};
当然,上面的情况只是我们按照自己的实际情况人为拆分了任务,在实际应用中,可以进行一些封装。ES6 的 Generator 函数提供了 yield 关键字,这个关键字可以让函数暂停执行,通过迭代器对象的 next 方法还可以让函数继续执行。利用这个特性,我们可以设计出方便使用的时间切片。
function timeSlicing (gen) {
if (typeof gen === 'function') gen = gen()
if (!gen || typeof gen.next !== 'function') return
return function next() {
const start = performance.now()
let res = null
do {
res = gen.next()
} while(!res.done && performance.now() - start < 25);
if (res.done) return
setTimeout(next)
}
}
timeSlicing(function* () {
for (let i = 0; i < 2000000000; i++) {
yield
}
parentLogger('time slicing done!')
})();
上面的代码中,通过 yield 关键字将任务暂停,从而让出主线程的控制权;通过定时器将任务重新放在任务队列中继续执行。使用时间切片后,主线程上不再有长任务,而是被切分成了无数个小任务,如下图:
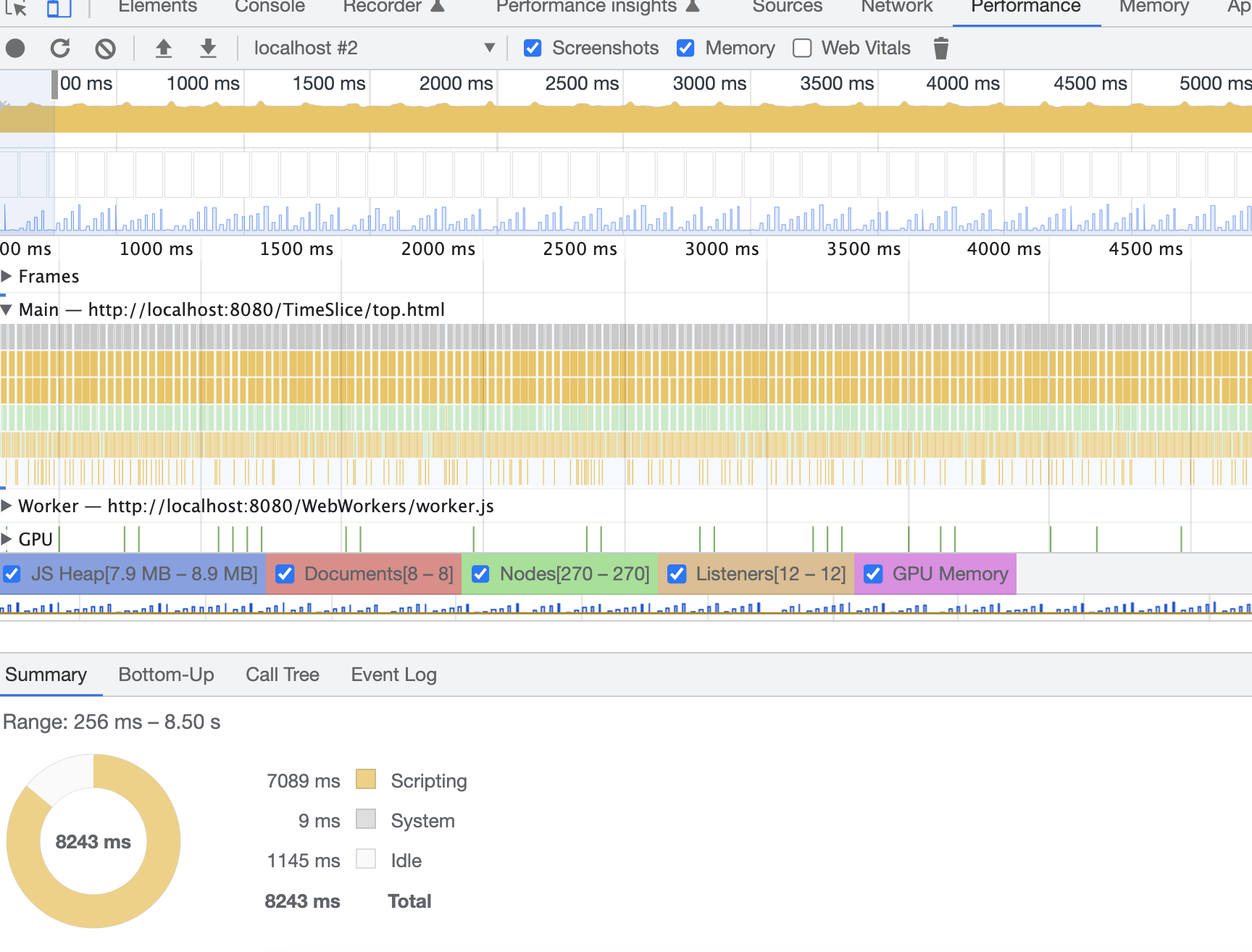
使用时间切片的缺点是,任务运行的总时间变长了,这是因为它每处理完一个小任务后,主线程会空闲出来,并且在下一个小任务开始处理之前有一小段延迟。但是为了保证页面的正常渲染,这种取舍是很有必要的。
还有很多实现时间切片的方法,比如 react 源码中的 Scheduler 模块也实现了时间切片(requestHostCallback),我们也可以使用 requestAnimationFrame 或者 requestIdleCallback 来实现。
# 减少重排重绘
首先我们来回顾下页面的渲染流程:
- 构建 DOM 树
- 样式计算
- 布局定位
- 图层分层
- 图层绘制
- 合成显示
当 CSS 属性改变时,重渲染会分为重排、重绘和直接合成三种情况,分别会从布局定位、图层绘制、合成显示开始,再走一遍下面的流程。
如何减少重排和重绘,主要的思路是将多次的 DOM 操作合并为一次,或者使需要被操作的元素脱离文档流以减少浏览器重绘与重排的次数。我这里列举了一些,因为大家比较熟悉,这里不再展开:
- 避免逐项更改样式,最好可以将样式列表定义为
class并一次性更改class - 尽量减少
table使用,table属性变化使用会直接导致布局重排或者重绘 - 避免循环操作
DOM,可以使用DocumentFragment, 在操作完成后再加入document - 避免循环读取
offsetLeft等会引起强制同步布局的属性,在循环之前把它们存起来
而直接合成可以避开重排和重绘阶段,只需要将多个图层再次合并,而后生成位图显示。这样的效率是最高的,因为是在非主线程上合成,并没有占用主线程的资源,另外也避开了布局和绘制两个子阶段,所以相对于重绘和重排,合成能大大提升绘制效率。
# 硬件加速
浏览器中图层一般包含两大类:渲染层以及复合层。如果要查看一个页面有哪些图层,可以在 Chrome 中选择 Layers 标签,左边是图层列表,右边是渲染结果,每一个黑色线框就是一个图层,选中图层后,右下角可以看到图层的详细信息(在 Layers 中看到的都是合成层)。
<style>
body {
margin: 0;
padding: 0;
}
.box {
width: 100px;
height: 100px;
background: rgba(240, 163, 163, 0.4);
border: 1px solid pink;
border-radius: 10px;
text-align: center;
}
#a {}
#b {
position: absolute;
top: 0;
left: 80;
z-index: 2;
}
#c {
position: absolute;
top: 0;
left: 160;
z-index: 3;
transform: translateZ(0);
}
#d {
position: absolute;
top: 0;
left: 240;
z-index: 4;
}
.description {
font-size: 10px;
}
</style>
<div id="a" class="box">A</div>
<div id="b" class="box">
B
<div class="description">z-index:2</div>
</div>
<div id="c" class="box">
C
<div class="description">z-index:3</div>
<div class="description">transform: translateZ(0)</div>
</div>
<div id="d" class="box">
D
<div class="description">z-index:4</div>
</div>
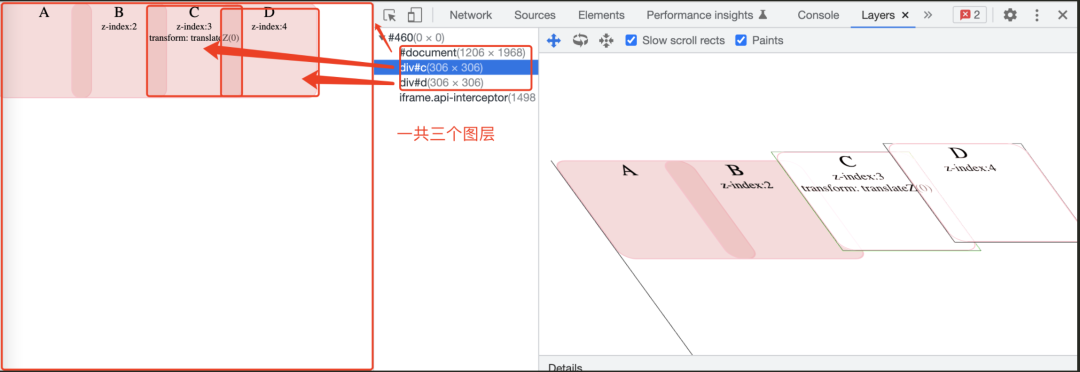 上图中,可以看到 AB 元素都在最底下的图层中,元素 C 是单独的一层,元素 D 又是一层。
上图中,可以看到 AB 元素都在最底下的图层中,元素 C 是单独的一层,元素 D 又是一层。
# 渲染层
通常情况下,并不是布局树的每个节点都包含一个图层,如果一个节点没有对应的层,那么这个节点就从属于父节点的图层。那么元素要满足什么条件,渲染引擎才会为它创建新的图层呢? 简单来说,元素拥有层叠上下文属性,或者需要被剪裁。
- 层叠上下文 文档中的层叠上下文由满足以下任意一个条件的元素形成:
条件
- 文档根元素
position值为absolute(绝对定位)或relative(相对定位)且z-index值不为auto的元素position值为fixed(固定定位)或sticky(粘滞定位)的元素(沾滞定位适配所有移动设备上的浏览器,但老的桌面浏览器不支持)flex (flex)容器的子元素,且z-index值不为autogrid (grid)容器的子元素,且z-index值不为autoopacity属性值小于 1 的元素(参见 the specification for opacity)mix-blend-mode属性值不为normal的元素- 以下任意属性值不为
none的元素:transformfilterbackdrop-filterperspectiveclip-pathmask / mask-image / mask-border isolation属性值为isolate的元素will-change值设定了任一属性而该属性在non-initial值时会创建层叠上下文的元素contain属性值为layout、paint或包含它们其中之一的合成值(比如contain: strict、contain: content)的元素
- 裁剪
需要剪裁的元素也会形成一个渲染层,也就是 overflow 不是 visible 的元素。比如有一个 200*200 的div,如果其中文字内容超出了 div 面积(overflow:auto或scroll),就产生了裁剪,渲染引擎会裁剪文字内容的一部分显示在 div 区域,此时,渲染引擎会为文字部分单独创建一个层,如果出现滚动条,滚动条也会被提升为单独的层。这样,滚动内容就不会重新计算整个文档的布局信息。
在上面的例子中,BCD 三个元素都是拥有 z-index 属性的定位元素,所以他们三个都形成了一个渲染层,加上 document 根元素形成的,一共是四个渲染层。
# 合成层
我们在开发者工具中看到的不是渲染层,而是合成层。只有一些特殊的渲染层才会被提升为合成层:
transform: 3D变换(translate3d | translateZ)will-change: opacity | transform | filter- 对 opacity | transform | fliter 应用了过渡和动画(transition/animation)
- video、canvas、iframe
还是上面的例子,C 元素使用了3D变换 transform: translateZ(0),于是被提升到一个单独的合成层, 但是 D 元素没有命中上面任何一条规则,却也是一个单独的合成层,这是因为还有一种隐式合成的情况:当出现一个合成层后,层级顺序高于它的堆叠元素就会发生隐式合成。因为 D 元素的 z-index 比 C 要高,而 C 是一个合成层,所以,D 也是一个合成层。
隐式合成会产生虚度合成层——页面中所有 z-index 高于它的节点全部被提升,这些合成层都是相当消耗内存和GPU的。因此,我们需要注意给合成层一个大的z-index值,避免出现隐式合成。
# 硬件加速
分层主要是为了处理页面中的一些复杂的效果,比如 3D 变换、页面滚动,或者使用 z-index 做 z 轴排序等,这些效果使得与之对应的 DOM 节点尺寸和坐标等不断更新。如果不分层,则需要重新计算整个布局树中每个元素的位置,而分层后,就只需要计算变换层中的元素位置信息。
在实际工作中,我们可以利用分层进行硬件加速(因为合成层会交给GPU(显卡)去处理,在硬件层面上开外挂)。我们可以通过给 DOM 元素加上某些 CSS 属性将其提升成一个合成层进行独立渲染。因为合成层的是 GPU 线程处理的,此时会释放主线程的资源,而且提升成合成层的元素发生回流、重绘都只影响这一层,渲染效率得到提升。
在下面的例子中,我们使用 animation 改变了 B 元素的宽度。
<style>
.box {
width: 100px;
height: 100px;
background: rgba(240, 163, 163, 0.4);
border: 1px solid pink;
border-radius: 10px;
text-align: center;
}
#a {
}
#b {
position: absolute;
top: 50;
left: 50;
z-index: 2;
animation: width-change 5s infinite;
}
@keyframes width-change {
0% {
width: 80px;
}
100% {
width: 120px;
}
}
.description {
font-size: 10px;
}
</style>
<div id="a" class="box">A</div>
<div id="b" class="box">
B
<div class="description">animation:width-change</div>
</div>
通过 Layers 中的 paint count 可以看到 #document图层的绘制次数一直在增加:
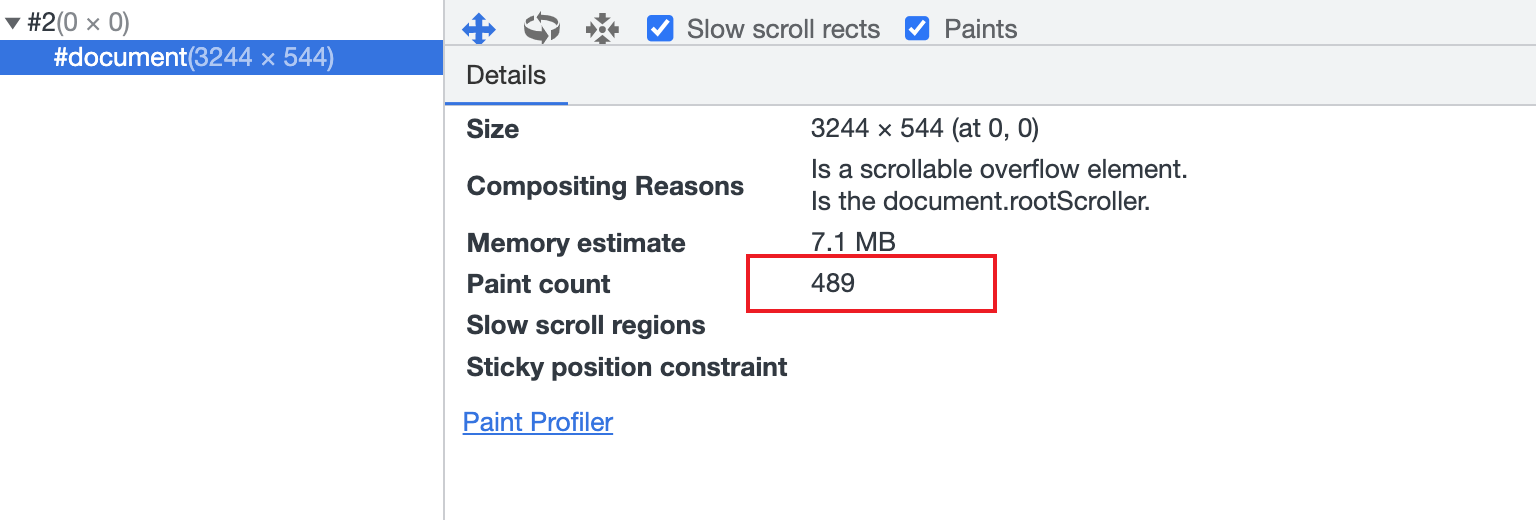
下面我们再给 B 元素加上 will-change:transform 开启硬件加速:
<style>
.box {
width: 100px;
height: 100px;
background: rgba(240, 163, 163, 0.4);
border: 1px solid pink;
border-radius: 10px;
text-align: center;
}
#a {}
#b {
position: absolute;
top: 50;
left: 50;
z-index: 2;
animation: width-change 5s infinite;
will-change: transform;
}
@keyframes width-change {
0% {
width: 80px;
}
100% {
width: 120px;
}
}
.description {
font-size: 10px;
}
</style>
<div id="a" class="box">A</div>
<div id="b" class="box">
B
<div class="description">animation:width-change</div>
</div>
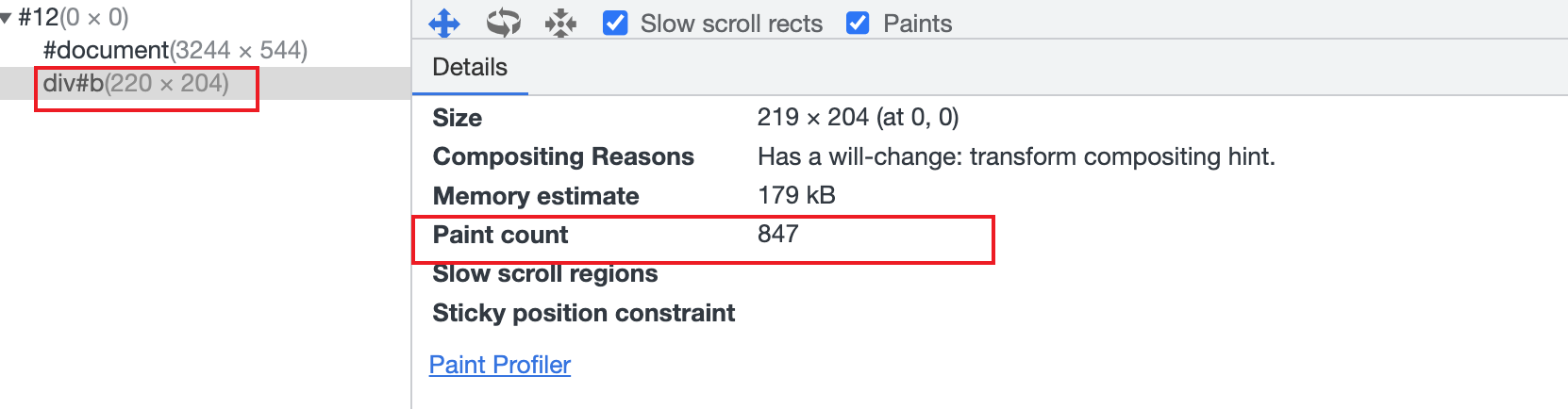
在上一节,我们介绍了减少重排和重绘,但如果重排和重绘没法避免时,可以利用这个队则使用硬件加速,让这个元素单独回流、重绘,减小绘制的影响范围。但是开启硬件加速依然要慎重,因为图层过多时将会占用大量内存,尤其在移动端会造成卡顿,让优化适得其反。
# 其他优化
频繁触发的操作,比如 scroll事件、窗口 resize 事件要进行节流、防抖
如果要绑定事件,比较好的方法就是用事件委托,把这个点击事件绑定到父节点(比如事件绑定在 ul 而不是 li 上),然后在执行事件的时候再去匹配判断目标元素,因为每个子节点绑定一个函数的话,会消耗更多内存
避免频繁的垃圾回收,如果在一些函数中频繁创建临时对象,那么垃圾回收器也会频繁地去执行垃圾回收策略。这样当垃圾回收操作发生时,就会占用主线程,从而影响到其他任务的执行,严重的话还会让用户产生掉帧、不流畅的感觉
图片的优化,对图片进行尺寸限制和降质处理,避免因为解压图片时内存爆增导致页面卡死或闪退的问题 (图片优化 (opens new window))
# 声明
本文转自不同页面共享渲染进程 (opens new window)(作者: YolkPie)