# 前端碎片知识集
我与我周旋久, 宁做我 — 殷浩

在前端的学习旅途中,我们时常会像漫游宇宙般穿梭在各种知识星球之间。有时,我们会发现一颗熠熠生辉的星辰,它可能是一种新的技术,一种优化方案,亦或是一段灵感的闪现。
于是,我将自己在前端旅途中搜集到的那些零散而珍贵的知识点,如同星辰般闪耀,融汇于这篇文章之中。这或许是一个小小的知识集合,但在我的成长过程中,它们无疑是重要的里程碑。
# 如何学习一门语言
- 语言优势和使用场景
- 基础语法(常量、变量、函数、类、流程控制)
- 内置库及API
- 框架及第三方库
- 开发环境搭建及调试
- 线上环境部署及监控
# XMLHttpRequest
异步请求中, xhr对象的readyState主要以下几个状态:
- UNSET - 0 尚未调用
open方法 - OPENED - 1
open方法已调用 - HEAD_RECEIVED - 2
send方法已调用,header已被接收 - LOAD - 3
responseText已有部分内容 - DONE - 4 请求完成
const xhr = new XMLHttpRequest()
xhr.open('POST', 'www.baidu.com', true) // 默认True异步
setRequestHeader("Content-type", "application/json");
xhr.onreadystatechange = function(){
if(xhr.readyState === 4){
if(xhr.staus === 200){
console.log('请求成功!')
}
}
}
xhr.send(JSON.stringify({name: 'zs'}))
xhr的readyState状态为DONE的时候, 也就等同于onload事件完成, 所以Xhr2的标准中可以使用onload
xhr.onload = function(){
if(xhr.staus === 200){
console.log('请求成功!')
}
}
# TCP三次握手
第一次握手: 客户端A将标志位SYN置为1,随机产生一个值为seq=J(J的取值范围为=1234567)的数据包到服务器,客户端A进入SYN_SENT状态,等待服务端B确认;
第二次握手: 服务端B收到数据包后由标志位SYN=1知道客户端A请求建立连接,服务端B将标志位SYN和ACK都置为1,ack=J+1,随机产生一个值seq=K,并将该数据包发送给客户端A以确认连接请求,服务端B进入SYN_RCVD状态。
第三次握手: 客户端A收到确认后,检查ack是否为J+1,ACK是否为1,如果正确则将标志位ACK置为1,ack=K+1,并将该数据包发送给服务端B,服务端B检查ack是否为K+1,ACK是否为1,如果正确则连接建立成功,客户端A和服务端B进入ESTABLISHED状态,完成三次握手,随后客户端A与服务端B之间可以开始传输数据了。
# TCP 四次挥手
第一次挥手: Client发送一个FIN,用来关闭Client到Server的数据传送,Client进入FIN_WAIT_1状态。
第二次挥手: Server收到FIN后,发送一个ACK给Client,确认序号为收到序号+1(与- SYN相同,一个FIN占用一个序号),Server进入CLOSE_WAIT状态。
第三次挥手: Server发送一个FIN,用来关闭Server到Client的数据传送,Server进入LAST_ACK状态。
第四次挥手: Client收到FIN后,Client进入TIME_WAIT状态,接着发送一个ACK给Server,确认序号为收到序号+1,Server进入CLOSED状态,完成四次挥手。
# Margin
margin-top和margin-left负值, 元素向上、向左移动margin-right负值, 右侧元素左移, 自身不受影响margin-bottom负值, 下方元素上移, 自身不受影响margin在弹性子元素项中auto值表示用margin去占用剩余空间
# 屏幕响应式适配
如今移动端响应式屏幕方案主要分为rem适配和vw适配
# rem适配
将css属性单位从
px改为rem动态获取用户设备的屏幕宽度
将项目的根字体大小设置为:
fontSize = width(真实设备的屏幕宽度) / width(设计稿的屏幕宽度) * fontSize(设计稿中的根字体大小)
根据这个等比例公式, 动态设置设备的根字体大小
document.documentElement.style.fontSize = Math.min(screen.width, document.documentElement.getBoundingClientRect().width) / 750 * 75(设计稿根字体大小) + 'px'
此处的设计稿中的根字体大小可以随意设置任意正数值, 但是必须与postcss-pxtorem这种插件中的配置值一致
// postcss.config.js
module.exports = {
plugins: {
'postcss-pxtorem': {
rootValue: 75, // 可以随意设置, 与动态值匹配即可
propList: ['*'],
minPixelValue: 2
}
}
};
# vw适配
vw适配方案将不需要动态的js来计算屏幕宽度, 只需要使用postcss-px-to-viewport插件, 按照设计稿的参数来配置即可
module.exports = {
plugins: {
'postcss-px-to-viewport': {
unitToConvert: 'px', // 要转化的单位
viewportWidth: 750, // UI设计稿的宽度
unitPrecision: 3, // 转换后的精度,即小数点位数
propList: ['*'], // 指定转换的css属性的单位,*代表全部css属性的单位都进行转换
viewportUnit: 'vw', // 指定需要转换成的视窗单位,默认vw
fontViewportUnit: 'vw', // 指定字体需要转换成的视窗单位,默认vw
selectorBlackList: [], // 指定不转换为视窗单位的类名,
minPixelValue: 1, // 默认值1,小于或等于1px则不进行转换
mediaQuery: true, // 是否在媒体查询的css代码中也进行转换,默认false
replace: true, // 是否转换后直接更换属性值
exclude: [/node_modules/], // 设置忽略文件,用正则做目录名匹配
landscape: false // 是否处理横屏情况
}
}
}
# rem + vw 适配
以下例子可以适配设计稿为750px的尺寸
<head>
<style>
/* 根字体大小设置为10vw */
html {
font-size: 10vw;
}
</style>
</head>
// postcss.config.js
module.exports = {
plugins: {
'postcss-pxtorem': {
rootValue: 75, // 可以随意设置, 与动态值匹配即可
propList: ['*'],
minPixelValue: 2
}
}
};
# BEM命名规范
BEM是块(block)、元素(element)、修饰符(modifier)的简写
- 中划线( - ): 仅作为连字符使用, 表示某个块或者某个子元素的多单词之间的连接记号(单词间隔)
- 双下划线( __ ): 双下划线用来连接块和块的子元素(连接块元素)
- 双中划线( -- ): 双中划线用来描述一个块或者块的子元素的一种状态(元素状态)
# 作用域分类
JS 总共有 9 种作用域,我们通过调试的方式来分析了下:
- Global 作用域: 全局作用域,在浏览器环境下就是 window,在 node 环境下是 global
- Local 作用域:本地作用域,或者叫函数作用域
- Block 作用域:块级作用域
- Script 作用域:let、const 声明的全局变量会保存在 Script 作用域,这些变量可以直接访问,但却不能通过 window.xx 访问
- Module 作用域:es module 模块运行的时候会生成 Module 作用域,而 commonjs 模块运行时严格来说也是函数作用域,因为 node 执行它的时候会包一层函数,算是比较特殊的函数作用域,有 module、exports、require 等变量
- Catch Block 作用域: catch 语句的作用域可以访问错误对象
- With Block 作用域:with 语句会把传入的对象的值放到单独的作用域里,这样 with 语句里就可以直接访问了
- Closure 作用域:函数返回函数的时候,会把用到的外部变量保存在 Closure 作用域里,这样再执行的时候该有的变量都有,这就是闭包。eval 的闭包比较特殊,会把所有变量都保存到 Closure 作用域
- Eval 作用域:eval 代码声明的变量会保存在 Eval 作用域
# 资源提示符
html标签包含很多资源提示符, 常用async、defer、preload、prefetch
script标签async不阻塞dom解析, 等script加载完成, 立即停止dom解析, 执行scriptscript标签defer不阻塞dom解析, 等script加载完成, 不会立即执行, 而是等到DomContentLoaded事件开始之前执行link标签preload尽快获取并缓存, 当前页面可能会用到link标签prefetch空闲时间获取并缓存, 下个页面可能会用到
# 经典三栏布局
经典的三栏布局常用双飞翼布局和圣杯布局
# 双飞翼布局
<style>
.middle,
.left,
.right {
float: left;
height: 300px;
}
.shuangfeiyi {
/* 生成BFC, 清除浮动 */
overflow: hidden;
}
.middle {
width: 100%
}
.left {
width: 200px;
margin-left: -100%;
}
.right {
width: 300px;
margin-left: -300px;
}
.middle__content {
margin: 0 300px 0 200px
}
</style>
<div class="shuangfeiyi">
<div class="middle">
<div class="middle__content"></div>
</div>
<div class="left"></div>
<div class="right"></div>
</div>
# 圣杯布局
<style>
.middle,
.left,
.right {
float: left;
height: 300px;
}
.shengbei {
/* 生成BFC, 清除浮动 */
overflow: hidden;
padding: 0 300px 0 200px;
}
.middle {
width: 100%;
background-color: antiquewhite;
}
.left {
width: 200px;
margin-left: -100%;
position: relative;
right: 200px;
background-color: pink;
}
.right {
width: 300px;
margin-right: -300px;
background-color: aquamarine;
}
</style>
<div class="shengbei">
<div class="middle">中间</div>
<div class="left">左侧</div>
<div class="right">右侧</div>
</div>
# React
# React Effect
当我们编写组件时,应该尽量将组件编写为纯函数。
对于组件中的副作用,首先应该明确:
是「用户行为触发的」还是「视图渲染后主动触发的」?
对于前者,将逻辑放在Event handlers中处理。
对于后者,使用useEffect处理。
# React 首行引入
新版本React函数式组件, 不需要每次在引入React库, 是因为babel做了处理, Automatic Runtime会自动注入行首的React引入逻辑
只需要将babel配置为:
"presets": [
["@babel/preset-react",{
"runtime": "automatic"
}]
],
在代码中就会自动引入
// 会被自动引入
import { jsx as _jsx } from "react/jsx-runtime";
# React 元素隐藏
在React中, 当一个元素为false、undefined、 null时, 该元素将不显示。 因此开发时,要注意元素判断条件是否为这几类值, 否则会导致bug
class App {
render() {
const { list } = this.state
return <div className="page-index-box">
{
// 该写法, 当length为0, 会显示0, 导致bug
list.length && list.map(() =>
<div>
{list.id} - {list.name}
</div>
)
}
</div>
}
}
# React SetState
假如一次事件中触发一次如上 setState ,在 React 底层主要做了那些事呢?
- 首先,setState 会产生当前更新的优先级(老版本用 expirationTime ,新版本用 lane )。
- 接下来 React 会从 fiber Root 根部 fiber 向下调和子节点,调和阶段将对比发生更新的地方,更新对比 expirationTime ,找到发生更新的组件,合并 state,然后触发 render 函数,得到新的 UI 视图层,完成 render 阶段。
- 接下来到 commit 阶段,commit 阶段,替换真实 DOM ,完成此次更新流程。
- 此时仍然在 commit 阶段,会执行 setState 中 callback 函数,如上的
()=>{ console.log(this.state.number) },到此为止完成了一次 setState 全过程。
更新的流程图如下:
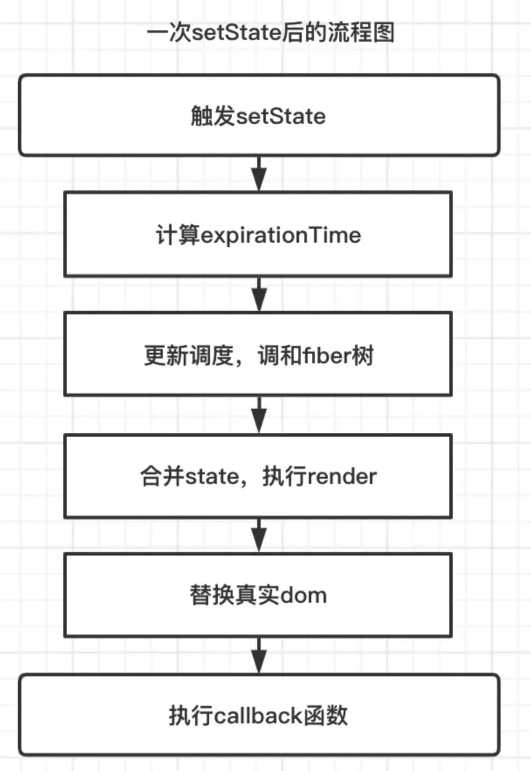
请记住一个主要任务的先后顺序,这对于弄清渲染过程可能会有帮助: render 阶段 render 函数执行 -> commit 阶段真实 DOM 替换 -> setState 回调函数执行 callback 。
# Node
# Node Babel的配置
- 安装依赖
pnpm i @babel/core @babel/preset-env @babel/plugin-transform-runtime -D
# @babel/runtime-corejs3会将core-js@作为依赖安装
pnpm i @babel/runtime-corejs3 -S
- 书写配置文件
module.exports = {
presets: [
[
'@babel/preset-env',
{
targets: {
node: "current"
},
// 关闭 @babel/preset-env 默认的 Polyfill 注入
useBuiltIns: "usage",
// 使用core-js@3提供polyfill
corejs: 3,
// 是否转换为其他模块, 可以转换成‘commonjs’、'amd'、‘umd’、‘systemjs’
modules: false
}
]
],
plugins: [
// 添加 transform-runtime 插件
[
'@babel/plugin-transform-runtime',
{ corejs: 3 }
]
]
}
# Node Esm模块开发
- Node中使用ESM模块开发, 需要处理常用的内置变量, 例如
__dirname或者__filename
import path from 'path'
const __filename = new URL(import.meta.url).pathname
const __dirname = path.dirname(__filename)
- Node ESM模块中使用
json文件应该怎么做?
// 对于 Node 17.5+,你可以使用导入断言
import pkg from './package.json' assert { type: 'json' };
export default {
external: Object.keys(pkg.dependencies)
};
// 如果版本低于17.5, 通用情况就使用fs读取
import { readFileSync } from 'node:fs';
const packageJson = JSON.parse(
readFileSync(new URL('./package.json', import.meta.url))
);
# Node Spawn双向通信
const { spawn } = require('child_process');
const svrCodeWatchProcess = spawn('npm', ['run', 'svr:watch'], { shell: process.platform === 'win32' });
// 父进程发送消息给子进程
svrCodeWatchProcess.stdin.write('Hello from parent process!');
// 子进程接收父进程消息
process.stdout.on('data', (data) => {
console.log('Received message from child process:', data.toString());
});
// 子进程发送消息给父进程
process.stdout.write('Message from child process');
// 父进程接收子进程消息
svrCodeWatchProcess.stdout.on('data', (data) => {
console.log('Received message from child process:', data.toString());
});
# 微前端
- 增量开发及迁移
- 独立构建发布
- 包容不同的技术栈
# HMR分类
HMR主要分为热重载和热替换, 两者的区别如下:
热重载: 代码变化重新加载整个应用, 会重刷整个页面, 导致状态和数据丢失
热替换: 只会替换修改的模块, 不重刷页面, 状态数据得以保留
# HMR热更新原理
热更新主要是由4个部分组成
- HMR Server 服务端
- Compiler 编译器
- Module 模块
- HMR Runtime 客户端
首先, 服务端和客户端会建立Websocket连接, 当代码文件发生变动, HMR Server告知HMR Runtime需要检查更新, HMR Runtime 发起一个请求,获取变更的模块信息JSON文件, 从JSON中获取到已经发生变更的模块;
此时, HMR Runtime异步下载需要更新的模块, 一切就绪后, HMR Server通过 WebSocket 通知 HMR Runtime 可以同步应用更新, HMR Runtime 将最新的模块进行替换,将老的模块解绑,最后更新应用 Hash,并开始以更新的模块为起点向上进行冒泡
如果, 在模块中有注册了 HMR module.hot.accept接口, 那么就会调用该接口来实现元素如何替换
# HMR整体流程
Webpack DevServer 的 HMR(Hot Module Replacement)是一种在开发过程中实现模块热替换的机制,它能够在不刷新整个页面的情况下,实时更新已经修改的模块。下面是 Webpack DevServer HMR 的主要流程:
启用 HMR: 在 Webpack 配置中,你需要启用 HMR 功能。这通常通过 webpack-dev-server 提供的 hot 参数来实现。例如:
// webpack.config.js
module.exports = {
// ...
devServer: {
hot: true,
},
// ...
};
启动开发服务器: 运行
webpack-dev-server命令启动开发服务器。开发服务器会将打包后的文件提供给浏览器,并监听文件变化。构建并打包:
Webpack会将项目的源代码进行构建和打包。每个模块都会生成一个唯一的 ID,并且在构建过程中会生成一些用于 HMR 的额外代码。HMR runtime 注入:
Webpack会在构建过程中,将HMR runtime(HMR 的运行时)注入到打包后的文件中。HMR runtime负责在浏览器端与开发服务器进行通信,接收更新,并触发模块的热替换。浏览器连接到开发服务器: 当你在浏览器中访问开发服务器时,浏览器会与开发服务器建立连接。这个连接使用
WebSocket协议,因为WebSocket具有实时双向通信的能力。监听文件变化: 开发服务器会监听项目源代码的变化,包括源代码中的
JavaScript文件、CSS文件等。文件更新推送: 当文件发生变化时,
Webpack DevServer会通过WebSocket将更新的模块信息推送给浏览器中的HMR runtime。模块热替换: 在接收到更新的模块信息后,
HMR runtime会根据这些信息进行模块热替换。它会移除旧的模块,加载新的模块,并应用新的变化,从而实现实时更新。这样,你就能在浏览器中看到最新的修改,而不需要刷新整个页面。应用更新:
HMR完成模块的热替换后,浏览器会将更新应用到页面中,从而实现无刷新的开发体验。
总的来说,Webpack DevServer HMR 的流程可以简化为:文件变化 -> HMR runtime 接收更新 -> 模块热替换 -> 浏览器应用更新。这样开发者就可以在保持应用状态的同时,实时地看到修改后的效果,提高开发效率。
# 逻辑运算规律
逻辑运算有几个常见的规律,其中包括以下几种:
- 交换律(Commutative Law):对于逻辑与(AND)和逻辑或(OR)运算,交换律成立:
A && B等价于B && AA || B等价于B || A
- 结合律(Associative Law):对于逻辑与(AND)和逻辑或(OR)运算,结合律成立:
(A && B) && C等价于A && (B && C)(A || B) || C等价于A || (B || C)
- 分配律(Distributive Law):对于逻辑与(AND)和逻辑或(OR)运算,分配律成立:
A && (B || C)等价于(A && B) || (A && C)A || (B && C)等价于(A || B) && (A || C)
- 吸收律(Absorption Law):对于逻辑与(AND)和逻辑或(OR)运算,吸收律成立:
A && (A || B)等价于AA || (A && B)等价于A
- 德摩根定律(De Morgan's Laws):逻辑非(NOT)的德摩根定律成立:
!(A && B)等价于!A || !B!(A || B)等价于!A && !BA && B等价于!(!A || !B)A || B等价于!(!A && !B)
# JS中的访问器属性
在 JavaScript 中,对象的访问器属性可以通过 Object.defineProperty 方法来定义,这是一种常见的方式。但是,还有其他方式可以定义对象的访问器属性。
除了使用 Object.defineProperty,还有以下两种方式来定义对象的访问器属性:
- 使用
get和set关键字:在 ES6(ECMAScript 2015)及以后的版本中,可以使用get和set关键字来定义对象的访问器属性。
const obj = {
firstName: 'John',
lastName: 'Doe',
get fullName() {
return this.firstName + ' ' + this.lastName;
},
set fullName(value) {
const [firstName, lastName] = value.split(' ');
this.firstName = firstName;
this.lastName = lastName;
}
};
console.log(obj.fullName); // 输出:John Doe
obj.fullName = 'Jane Smith';
console.log(obj.firstName); // 输出:Jane
console.log(obj.lastName); // 输出:Smith
在上述示例中,通过在对象字面量中使用 get 和 set 关键字,定义了 fullName 属性的获取和设置逻辑。
- 使用 class 中的 getter 和 setter 方法:在使用类(class)定义对象时,可以通过 getter 和 setter 方法来定义访问器属性。
class Person {
constructor(firstName, lastName) {
this._firstName = firstName;
this._lastName = lastName;
}
get fullName() {
return this._firstName + ' ' + this._lastName;
}
set fullName(value) {
const [firstName, lastName] = value.split(' ');
this._firstName = firstName;
this._lastName = lastName;
}
}
const person = new Person('John', 'Doe');
console.log(person.fullName); // 输出:John Doe
person.fullName = 'Jane Smith';
console.log(person.fullName); // 输出:Jane Smith
在上述示例中,通过在 class 中定义 getter 和 setter 方法,实现了访问器属性 fullName。
总结:除了使用 Object.defineProperty 方法外,JavaScript 中的对象的访问器属性可以通过 get 和 set 关键字以及 class 中的 getter 和 setter 方法来定义。这些方法都可以用来创建和操作对象的访问器属性, 且get或者set后面必须指定属性名。
# 严格模式
类和模块的内部,默认就是严格模式,所以不需要使用use strict指定运行模式。只要你的代码写在类或模块之中,就只有严格模式可用。考虑到未来所有的代码,其实都是运行在模块之中,所以 ES6 实际上把整个语言升级到了严格模式。
# Iterator 和 Generator
生成器用于创建迭代器, 调用生成器会返回迭代器, 部署了迭代器接口[Symbol.Iterator]函数的就可以通过for...of直接遍历, 在生成器内部, 为了方便使用, 可以是用yield*直接调用迭代器, 等同于多条yield
# 缓存图片
在浏览器中, 可以使用三种方式创建图片
- innerHTML
- new Image
- document.createElement
创建好图片后, 将需要缓存的所有图片, 添加上src属性, 浏览器就会去下载对应的图片。当使用图片时, 直接引用这些图片对象即可
// 缓存图片
const imgList = Array.from({ length: 10 }, (_, index) => {
const img = new Image()
img.src = `https://picsum.photos/id/${index}/200/300`
return img
})
# Vue子组件异步调用
Vue中父组件如果需要调用子组件的异步方法, 或者父组件需要等待子组件某种Ready状态时, 再执行某些事情, 可以按照如下几种方式
# 子组件发送事件
// a.vue
<template>
<div>
这是a页面
<childB ref="childB" @onReady="toPlay"/>
</div>
</template>
<script>
import childB from './b'
export default {
methods: {
toPlay(){
const { play } = this.$refs.childB
play()
}
},
components: {
childB,
},
}
</script>
// b.vue
<template>
<div>这是b页面</div>
</template>
<script>
export default {
beforeCreate(){
this.init()
},
methods: {
init() {
setTimeout(() => {
this.$emit("onReady")
}, 2000)
},
play() {
console.log('ok')
},
},
}
</script>
# 子组件暴露Promise
// a.vue
<template>
<div>
这是a页面
<childB ref="childB" />
</div>
</template>
<script>
import childB from './b'
export default {
mounted() {
const { init, play } = this.$refs.childB
init().then(play)
},
components: {
childB,
},
}
</script>
// b.vue
<template>
<div>这是b页面</div>
</template>
<script>
export default {
methods: {
init() {
return new Promise(resolve => {
setTimeout(() => {
resolve()
}, 2000)
})
},
play() {
console.log('ok')
},
},
}
</script>
# 子组件内部await
// a.vue
<template>
<div>
这是a页面
<childB ref="childB" />
</div>
</template>
<script>
import childB from './b'
export default {
mounted() {
this.$refs.childB.play()
},
components: {
childB,
},
}
</script>
// b.vue
<template>
<div>这是b页面</div>
</template>
<script>
const promisArr = (n = 1) =>
Array.from({ length: n }, (_, id) => {
let resolve, reject
const promise = new Promise((e, j) => ((resolve = e), (reject = j)))
return { id, resolve, reject, promise }
})
const { id, reject, resolve, promise } = promisArr().pop()
export default {
created() {
this.init()
},
methods: {
init() {
setTimeout(() => {
resolve('hello')
}, 2000)
},
async play() {
const res = await promise
console.log('ok', res)
}
}
}
</script>
# 字符串码点和码元
字符编码系统将一个 Unicode码位 (opens new window)编码为一个或者多个码元
JavaScript字符串使用的编码系统是UTF-16, 即表示一个码元, 也就是两个个字节(2^16 = 65535)
并非 Unicode 定义的所有码位都适合单个 UTF-16 来编码
如果字符串包含非 ASCII字符,那么这个字符可能是由两个码元组成, 即四个字节, 这种两个码元组成的称为码点
我们常用的API, 都是使用的单个码元作为单位编码, 例如:length表示码元个数、slice以码元作为单位
为了表示完整的字符串, JS提供了一个码点相关的API
- String.prototype.codePointAt 读取字符的码点值
- String.prototype.fromCodePoint 从码点值转化为字符
const str = `🎂`
str[0] // 输出为�, 会乱码
str.codePointAt(0) // 127874大于了65535, 因此使用两个码元编码
// 给字符串添加码点长度的属性
Reflect.defineProperty(String.prototype, 'codePointLength', {
get(){
const TWO_BYTE = 65535
let len = 0
for(let i = 0; i < this.length; ){
const codePonitValue = this.codePointAt(i)
i += codePonitValue > TWO_BYTE ? 2 : 1
len++
}
return len
}
})
# 内存泄露
常见内存泄露的场景如下:
- 意外的全局变量
- 遗忘的定时器
- 使用不当的闭包
- 已卸载DOM的持久引用
此处第四点, 如果有变量引用一个DOM元素, 后来DOM元素被移除, 就会发生内存泄露
因此, 日常开发中, 记得使用WeakSet和WeakMap来存储这种场景下的DOM元素
# Visual Studio Code
# 重构相关
Visual Studio Code征对重构类、快速定位报错行、征对报错行进行处理、修改函数名称等等征对代码重构优化操作的快捷键收录到此
- 重构:
control + shift + R - 定位代码警告:
F8 - 快速修复:
cmd + . - 重命名符号:
F2 - 跳转到符号:
shift + cmd + O - 跳转到文件:
cmd + P - 跳转到行:
control + G - 显示所有符号Symbol:
cmd + T - 显示命令板:
cmd + shift + P - 单词切换大写:
control + shift + U - 单词切换小写:
control + shift + I
更多细节阅读Visual Studio Code文档: typescript-refactoring (opens new window)
# 常用调试配置
{
// 使用 IntelliSense 了解相关属性。
// 悬停以查看现有属性的描述。
// 欲了解更多信息,请访问: https://go.microsoft.com/fwlink/?linkid=830387
"version": "0.2.0",
"configurations": [
{
"name": "ChromeCanary调试",
"request": "launch",
"type": "chrome",
"url": "http://localhost:8888",
"webRoot": "${workspaceFolder}",
"userDataDir": false,
"runtimeExecutable": "canary",
"runtimeArgs": [
"--auto-open-devtools-for-tabs"
// 无痕模式
// "--incognito"
]
},
{
"name": "ChromeStable调试",
"request": "launch",
"type": "chrome",
"url": "http://localhost:8081",
"webRoot": "${workspaceFolder}/projects/wds-html/src",
// "preLaunchTask": "debug", // 添加的配置,在执行之前需要启动项目,这个是启动项目用的任务。
"sourceMapPathOverrides": {
// 把调试的文件 sourcemap 到的路径映射到本地的文件
"webpack:///./*": "${webRoot}/*",
"webpack:///src/*": "${webRoot}/*",
"webpack:///./src/*": "${webRoot}/*",
"webpack:///*": "*",
"webpack:///./~/*": "${webRoot}/node_modules/*"
} // 添加的配置,为了找到打包文件和源代码之间的关联,使断点生效。
},
{
"name": "Static调试",
"request": "launch",
"type": "chrome",
"runtimeExecutable": "canary",
"userDataDir": false,
"webRoot": "${workspaceFolder}",
"file": "${workspaceFolder}/code-snippets/htmls/vue滑动卡片跟随.html",
"pathMapping": {
// 服务的路径映射到本地的目录
"/static/js/": "${workspaceFolder}/src/"
}
},
{
"type": "node",
"request": "launch",
"name": "Node调试",
// 这里配置脚本位置(package.json->main)
"program": "${file}",
// 传给program的参数
// "args": [
// "-l https://juejin.cn/book/7070324244772716556/section/7148818133343158286"
// ],
"cwd": "${workspaceFolder}",
"skipFiles": [
// "<node_internals>/**"
],
// console 要设置为 integratedTerminal,这样日志会输出在 terminal,就和我们手动执行 npm run xxx 是一样的
// 不然,日志会输出在 debug console。颜色啥的都不一样
"console": "integratedTerminal"
},
{
"name": "Pnpm调试",
"request": "launch",
"cwd": "${workspaceFolder}/projects/webpack-error-test",
"env": {
"ENV_VAR": "1123"
},
// "envFile":"...",
"runtimeArgs": ["run-script", "build-dev"],
"runtimeExecutable": "pnpm",
"skipFiles": [],
"type": "node",
"resolveSourceMapLocations": ["${workspaceFolder}/**"],
"stopOnEntry": true
},
{
"name": "Typescript调试",
"program": "${file}",
"request": "launch",
"sourceMaps": true,
// 默认是 node, 从 PATH 的环境变量中查找对应名字的 runtime 启动
"runtimeExecutable": "esno", // ts-node也可以, 执行效率没有esno快
"skipFiles": ["<node_internals>/**", "**/node_modules/**"],
"resolveSourceMapLocations": ["${workspaceFolder}/**"],
"type": "node",
// 入口处断住
"stopOnEntry": true
},
{
// require(child_process).exec('xxx.js')
"name": "Child进程调试",
"program": "${file}",
"request": "launch",
"skipFiles": ["<node_internals>/**"],
"type": "node",
"console": "internalConsole",
"autoAttachChildProcesses": true
},
{
"name": "Pick进程调试",
"processId": "${command:PickProcess}",
"request": "attach",
"skipFiles": ["<node_internals>/**"],
"type": "node"
},
{
"name": "Vite调试",
"type": "chrome",
"request": "launch",
"runtimeExecutable": "canary",
"runtimeArgs": ["--auto-open-devtools-for-tabs"],
"userDataDir": false,
"url": "http://localhost:3000",
// vite 时会有一些热更之类的文件,也会被映射到源码,导致断在某名奇妙的地方
// 把 webRoot 配置成任意的一个不存在的目录,比如 noExistPath,这样这些文件就不会被错误的映射到源码里了。
// 算是一种 hack 的处理方式
"webRoot": "${workspaceFolder}/noExistPath"
},
{
// 可以调试多个项目, 先自己在浏览器打开相应的页面
"type": "chrome",
// 连接某个已经在调试模式启动的 url 进行调试
"request": "attach",
"name": "Vite 模块联邦",
"port": 9222,
// "preLaunchTask": "launch-chrome",
"webRoot": "${workspaceFolder}/projects/module-federation/",
"skipFiles": [],
"sourceMapPathOverrides": {
"webpack:///./*": "${webRoot}/*",
"webpack:///src/*": "${webRoot}/*",
"webpack:///./src/*": "${webRoot}/*",
"webpack:///*": "*",
"webpack:///./~/*": "${webRoot}/node_modules/*"
}
},
{
// nodemon --inspect-brk=9229 x.js
// nodemon --inspect=9229 x.js
"name": "Server附加调试",
"port": 9229,
"request": "attach",
"skipFiles": ["<node_internals>/**"],
"type": "node"
}
]
}
# 快捷键文档
如果需要查询Chrome的所有快捷键, 可以在vscode中按下cmd + k cmd + r组合快捷键
通过Chrome直达Visual Studio Code快捷键官方文档 (opens new window)
# 单点登录三种方式
# Session + Cookie
选用该Session + Cookie方案的系统, 用户登录都会到统一认证中心。 认证中心产生UID和SessionId, 认证中心存储登录信息到数据库中, 并将UID返回到Cookie中
当请求子系统接口时, 会将Cookie发送到子系统, 子系统通过查询认证中心UID是否登录, 再进行下一步的处理
优缺点
很容易控制用户在线状态,缺点扩容花费高,子系统扩容会导致认证中心也必须扩容
# Token
选用该Session + Cookie方案的系统, 用户登录依旧到统一认证中心, 认证中心产生Token返回给客户端, 客户端存储到本地用于后续请求
当请求子系统接口时, 会将Token发送到子系统, 子系统能直接验证Token是否有效, 因为子系统和认证中心有一套约定的密钥,因此不需要再次请求认证中心
优缺点
方便子系统扩容,缺点是不容易控制用户状态,如果想注销用户的状态,只能等待Token过期
# AccessToken + RefreshToken
选用该AccessToken + RefreshToken方案的系统, 用户登录依旧到统一认证中心, 认证中心产生短效期的AccessToken(分钟)和长效期RefreshToken(天)返回给客户端, 客户端将两个Token都存储到本地用于后续请求
当请求子系统接口时, 客户端只会将短效期的AccessToken发送到子系统, 子系统能直接验证AccessToken是否有效, 由于短效AccessToken时间短, 因此会经常过期
当短效AccessToken过期时, 客户端需要使用RefreshToken向认证中心发送请求, 获取最新的AccessToken, 再次存储到本地, 供后续请求使用
优缺点
子系统容易扩容,还可以控制用户登出状态, 因为AccessToken时效短, 因此方案更佳
# Jest
# 项目集成
在一个typescript项目中集成Jest的步骤如下
- 安装依赖
pnpm add jest @types/jest -D
- 添加
Babel和Typescript支持
# 如果项目中在使用`jest-cli`,推荐搭配`babel-jest`,它将使用 `Babel` 自动编译 `JS` 代码
pnpm add babel-jest @babel/core @babel/preset-env @babel/preset-typescript -D
- 添加
Babel配置
// 为Node配置Babel后, 就可以随意在Node中使用ESM模块
module.exports = {
presets: [
['@babel/preset-env', {targets: {node: 'current'}}],
'@babel/preset-typescript',
],
};
集成部分请查阅Jest官网: 使用Typescript (opens new window)
# 小技巧
- 模拟函数 jest.fn
- 跳过当前用例 it.skip
- 仅测试当前用例, 后续不测试 it.only
- 监听所有测试文件 jest --watchAll
- 测试覆盖率 jest --coverage
# 断言API
====================真实性Truthiness=============
toBeNull // 是否为Null
toBeUndefined
toBeDefined
toBeFalsy // 为假 ensure a value is false in a boolean context
toBeTruthy
====================数字Numbers====================
toBeGreaterThan // 大于
toBeGreaterThanOrEqual // 大于等于
toBeLessThan // 小于
toBeLessThanOrEqual // 小于
toBe //
toEqual //
toBeCloseTo // 接近的数,解决js小数的浮点问题
closeTo // 浮点数compare float point numbers
====================数组Arrays&迭代iterables=============
toContain // 对象是否在数组中使用 check an item is in an array
not.arrayContaining // 不包含该元素 array is not a subset子集 of the received array
====================异常Exceptions=============
toThrow // 调用时必须抛出异常 a function throws when it is called
not.toThrow // 不要抛出异常
====================方法Function=============
assertions // 必须要调用测试 verifies a certain number of assertion are called
hasAssertions // 至少调用了一个方法 at least one assertion is called
toHaveBeenCalled // 被调用的
====================对象Object====================
toEqual // 相等 Object.is
toStrictEqual // 对象的结构是否完全相等 test the object have the same types&structure
objectContaining // 预期对象存在接收对象 received object contains properties in expected object
toBeInstanceOf // 对象是否为类的实例 check the object is an instance of a class
toMatchObject // 对象匹配另一个对象的子集a js Object matches a subset of the properties of an object
====================字符串String====================
stringMatching // 匹配字符串\正则 matches string\Regular Expression
toMatch // 字符串匹配器 a string matches a regular expression
====================更多More====================
toMatchSnapshot //匹配最近的快照 matches the most recent snapshot
# 钩子函数
:::info BeforeAll
所有的测试用例执行之前执行的方法 :::
:::info AfterAll
所有的测试用例执行完后执行的方法,如果传入的回调函数返回值是 Promise
或 Generator,Jest 会等待 Promise Resolve 再继续执行
:::
:::info BeforeEach
BeforeEach 在每个测试完成之前都运行一遍
:::
:::info AfterEach
与 AfterAll 相比,AfterEach 在每个测试完成后都运行一遍
:::
# TDD开发
TDD (Test Driven Development)是一种开发流程, 在进行开发工作之前,编写测试,预先模拟欲测试的场景
- 书写测试用例
- 编写源码通过用例
- 重构源码
# 测试覆盖率
代码覆盖率是一项指标,可以帮助您了解测试了多少源代码。这是一个非常有用的指标,可以帮助您评估测试套件的质量, 即检测测试是否全面
- 函数覆盖率:已定义的函数中有多少被调用
- 语句覆盖率:程序中有多少语句已执行
- 分支覆盖率:控制结构的分支(例如 if 语句)中有多少已执行
- 条件覆盖率:已经测试了多少布尔子表达式的真值和假值
- 行覆盖率:已经测试了多少行源代码
这些指标通常表示为实际测试的项目数量、代码中找到的项目以及覆盖率百分比(测试的项目/找到的项目)
jest 和 karama 都是基于 istanbul 做的覆盖率检测
# Rollup
# 插件顺序
Rollup配置多个plugins的情况下, 插件默认是从前往后执行, 因此项目中的插件必须配置一定的顺序。如果后续的插件依赖前面的插件, 需要注意先后顺序。一般的工程中,都会使用commonjs和resolve等等插件, 所以这几个插件的顺序如下
// resolve让项目支持使用node_modules中的模块
import resolve from '@rollup/plugin-node-resolve';
// rollup使用的是es6的模块化, 插件commonjs能够让项目能够支持使用cjs源码的npm库
import commonjs from '@rollup/plugin-commonjs';
export default {
input: 'main.js',
plugins: [
resolve(),
commonjs()
],
output: {
file: 'bundle.js',
format: 'cjs'
}
}
# 常用插件
下面罗列项目中常用的插件及配置, 更多插件请关注官方推荐插件列表 (opens new window)
import path from 'path';
import alias from '@rollup/plugin-alias';
import commonjs from '@rollup/plugin-commonjs';
import postcss from 'rollup-plugin-postcss';
import serve from 'rollup-plugin-serve';
import livereload from 'rollup-plugin-livereload';
import del from 'rollup-plugin-delete';
import babel from '@rollup/plugin-babel';
import typescript from '@rollup/plugin-typescript';
import { nodeResolve } from '@rollup/plugin-node-resolve';
import terser from '@rollup/plugin-terser';
import replace from '@rollup/plugin-replace';
import legacy from '@rollup/plugin-legacy';
import json from '@rollup/plugin-json';
import eslint from '@rollup/plugin-eslint';
import image from '@rollup/plugin-image';
export default {
input: './src/main.js', // 入口文件
output: {
file: './dist/bundle.js', // 打包后的存放文件
//dir: './dist', // 多入口打包必需加上的属性
format: 'cjs', // 输出格式 amd es6 iife umd cjs
name: 'bundleName', // 如果iife,umd需要指定一个全局变量
sourcemap: true, // 是否开启代码回溯
},
plugins: [
replace({
'process.env.NODE_ENV': JSON.stringify('production'),
__buildDate__: () => JSON.stringify(new Date()),
__buildVersion: 15
}),
// 支持从node_modules引入其他的包
nodeResolve(),
typescript({
exclude: 'node_modules/**',
include: 'src/**',
}),
// 支持common.js
// 在 rollup 中引用 commonjs 规范的包。该插件的作用是将 commonjs 模块转成 es6 模块。
commonjs({
throwOnError: true,
}),
// 支持eslint
eslint(),
// 支持加载图片
image(),
// es6语法转义
babel({
exclude: 'node_modules/**',
extensions: ['.js', '.jsx'],
presets: ['@babel/preset-env', '@babel/preset-react'],
}),
// 让项目中可以导入json文件
json(),
// 支持加载css,添加前缀等
postcss(),
// 有时,您会发现旧时代的一段有用的代码片段,在像 npm 这样的新技术出现之前。
// 这些脚本通常会将自己公开为var someLibrary = ...或window.someLibrary = ...,
// 期望其他脚本将从全局命名空间获取对库的引用。
// 将它们转换为模块通常很容易。但何苦呢?您只需添加legacy插件并进行相应配置,它就会自动变成模块。
legacy({ 'vendor/some-library.js': 'someLibrary' }),
// 打包前清空目标目录
del({ targets: 'dist/*', verbose: true }),
// 压缩js
terser(),
// 启动本地服务
serve({
contentBase: '', //服务器启动的文件夹,默认是项目根目录,需要在该文件下创建index.html
port: 8020, //端口号,默认10001
}),
// watch目录,当目录中的文件发生变化时,刷新页面
livereload('dist'),
// 使用别名
alias({
entries: [{ find: '@', replacement: path.join(__dirname, 'src') }],
}),
],
// 告诉rollup不要将此lodash打包,而作为外部依赖,在使用该库时需要先安装相关依赖
external: ['react']
};
# 组件按需加载
babel常见的按需加载的包有两个, babel-plugin-component和babel-plugin-import。该插件在babel做代码转换时,通过读取AST并收集归属于特定的libraryName的有效imported,然后进行命名转换、生成组件和样式的import 代码、移除多余imported等
两者大致的区别如下
- babel-plugin-component 主要用于
element-ui组件的按需加载, 与babel-plugin-import同一作者, 核心逻辑相同, 已不再维护 - babel-plugin-import 兼容了多个组件库, 例如
antd、antd-mobile、lodash、material-ui
# CSS Tree Shaking
Babel依靠AST技术完成对Javascript代码的遍历分析。 而在样式的世界中, PostCSS也起到了Babel的作用。
PostCSS提供了一个解析器, 能够将CSS解析成AST, 我们可以通过PostCSS插件对CSS对应的AST进行操作, 实现
Tree Shaking。这里主要记录在Webpack中如何配置CSS Tree Shaking
- 安装依赖
npm i purgecss-webpack-plugin -D
- 修改
webpack配置文件
const path = require("path");
const glob = require("glob");
const MiniCssExtractPlugin = require("mini-css-extract-plugin");
const { PurgeCSSPlugin } = require("purgecss-webpack-plugin");
const PATHS = {
src: path.join(__dirname, "src"),
};
module.exports = {
entry: "./src/index.js",
output: {
filename: "bundle.js",
path: path.join(__dirname, "dist"),
},
optimization: {
splitChunks: {
cacheGroups: {
styles: {
name: "styles",
test: /\.css$/,
chunks: "all",
enforce: true,
},
},
},
},
module: {
rules: [
{
test: /\.css$/,
use: [MiniCssExtractPlugin.loader, "css-loader"],
},
],
},
plugins: [
new MiniCssExtractPlugin({
filename: "[name].css",
}),
new PurgeCSSPlugin({
paths: glob.sync(`${PATHS.src}/**/*`, { nodir: true }),
}),
],
};
# JS Tree Shaking
Webpack中, 如果代码中包含副作用, 可以利用package.json的sideEffects属性告诉工程化工具, 哪些模块具有副作用, 哪些模块没有副作用并可以被Tree Shaking优化
# 副作用声明
- 表示全部模块均没有副作用
{
"name": "my-package",
"sideEffects": false
}
- 表示部分模块具有副作用
{
"name": "my-package",
"sideEffects": ["./src/some-side-effectful-file.js", "*.css"]
}
# 不利于Tree Shaking情况
以下情况都不利于进行Tree Shaking处理
- 导出一个包含多个属性和方法的对象
export default {
add(a, b){
return a + b
},
subtract(a, b){
return a - b
}
}
- 导出一个包含多个属性和方法的类
export default class {
add(a, b){
return a + b
}
subtract(a, b){
return a - b
}
}
- 使用
export default方法导出
export default xxx
鉴于上述的情况, 更推荐遵循原子化和颗粒化原则导出
export function add(a, b){
return a + b
}
export function subtract(a, b){
return a - b
}
# append 和 appendChild
Element.append 方法在 Element的最后一个子节点之后插入一组 Node 对象或 DOMString 对象。被插入的 DOMString 对象等价为 Text (en-US) 节点
与 Node.appendChild() 的差异:
Element.append()允许追加DOMString对象,而Node.appendChild()只接受Node对象Element.append()没有返回值,而Node.appendChild()返回追加的Node对象Element.append()可以追加多个节点和字符串,而Node.appendChild()只能追加一个节点
# LocalStorage 和 SessionStorage
LocalStorage和SessionStorage都是Web Storage API的一部分, 用于在浏览器中存储数据, 且存储都是关联到域名的
LocalStorage存储的数据没有过期时间, 除非手动清除, 否则一直存在SessionStorage存储的数据在会话结束时会被清除, 会话结束指浏览器关闭或者标签页关闭
而征对于同一个域名, LocalStorage和SessionStorage的区别如下
LocalStorage存储的数据在不同的Tab页面中是共享的, 即一个Tab页面中存储的数据, 另一个Tab页面可以访问到SessionStorage存储的数据在不同的Tab页面中是不共享的,Tab页无法访问同源的其他Tab页数据
特殊情况
以下两种情况下打开的新Tab页, SessionStorage会被复制到新的Tab页面中
window.open打开新的同源Tab页<a href="samesite url" rel=”opener” target="_blank">new tab</>打开新的Tab页
# 函数参数长度
一个 Function 对象的 length 属性表示函数期望的参数个数,即形参的个数
这个数字不包括剩余参数,只包括在第一个具有默认值的参数之前的参数
相比之下,arguments.length 是局限于函数内部的,它提供了实际传递给函数的参数个数
# ParseInt 和 Math.floor
两者都能获取小数的整数部分, 但是有以下不同点
Math.floor无论正负, 均向下取最接近的整数。 取随机整数[min,max]场景, 只能用该方法ParseInt对于负数, 会向上取整到最接近的整数。 对于正数, 会向下取整到最接近的整数
# Switch-Case非常规写法
本段落来记录Switch...Case的非常规写法
# 无Break语句
该场景下, Switch...Case会从第一个匹配的Case子语句开始, 执行后续所有的Case语句, 而不需要判断是否满足Case条件, 直到遇到Break语句或者Switch结束
应该特别注意连写Case的场景, 等同于多个条件的逻辑或运算
const fruittype = "Apples"
switch (fruittype) {
case "Oranges":
console.log("Oranges are $0.59 a pound.");
case "Apples":
console.log("Apples are $0.32 a pound.");
case "Bananas":
console.log("Bananas are $0.48 a pound.");
case "Cherries":
console.log("Cherries are $3.00 a pound.");
// 逻辑上等同于if(fruittype === "Mangoes" || fruittype === "Papayas")
case "Mangoes":
case "Papayas":
console.log("Mangoes and Papayas are $2.79 a pound.");
break;
default:
console.log("Sorry, we are out of " + fruittype + ".");
}
// Apples are $0.32 a pound.
// Bananas are $0.48 a pound.
// Cherries are $3.00 a pound.
// Mangoes and Papayas are $2.79 a pound.
# 前置Default语句
该场景下, Switch...Case中, Default语句放在开头, 其效果与放最后没有区别, 在没找到匹配的Case语句时, 会执行Default语句
需要注意, Case后面的子语句可以加上块作用域的括号, 来避免变量冲突
const fruittype = "Apples"
switch (fruittype) {
default: {
console.log("Sorry, we are out of " + fruittype + ".");
break;
}
case "Oranges": {
console.log("Oranges are $0.59 a pound.");
break;
}
case "Apples": {
console.log("Apples are $0.32 a pound.");
break;
}
}
// Apples are $0.32 a pound.
# 网页位置DOM属性
网页位置中, 需要注意五类属性, 分别是Window、Screen、Element、Event元素、Document
# 屏幕尺寸 Screen
screen.width屏幕宽度screen.height屏幕高度screen.availWidth屏幕可用宽度screen.availHeight屏幕可用高度
# 窗口尺寸 Window
window.screenTop窗口顶部距屏幕顶部的距离window.screenLeft窗口左侧距屏幕左侧的距离window.innerWidth窗口中可视区域的宽度window.innerHeight窗口中可视区域的高度(与浏览器是否显示菜单栏等因素有关)window.outerWidth浏览器窗口本身的宽度(可视区域宽度+浏览器边框宽度)window.outerHeight浏览器窗口本身的高度(可是区域高度+浏览器菜单栏等高度)
# 元素尺寸 Element
此处使用div来表示某一个元素
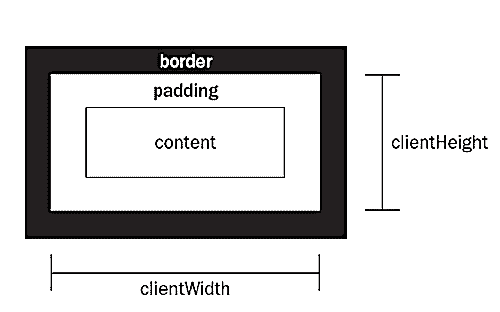
div.clientWidth在页面上返回元素的可视宽度(内容宽度+内边距)div.clientHeight在页面上返回元素的可视高度(内容高度+内边距)div.offsetWidth返回元素的宽度包括边框和填充(内容宽度+内边距+边框宽)div.offsetHeight返回元素的高度包括边框和填充(内容高度+内边距+边框高)div.scrollWidth返回元素的整个滚动宽度(包括带滚动条不可见的部分)div.scrollHeight返回元素的整个滚动高度(包括带滚动条不可见的部分)div.scrollTop当元素包含竖向滚动条时, 向下滚动后离开视野的区域高度div.scrollLeft当元素包含横向滚动条时, 向左滚动后离开视野的区域宽度
如何获取网页的绝对位置:
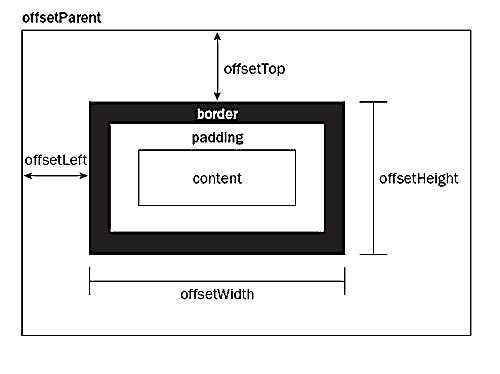
function getElementLeft(element) {
let actualLeft = element.offsetLeft;
let current = element.offsetParent;
while (current !== null) {
actualLeft += current.offsetLeft;
current = current.offsetParent;
}
return actualLeft;
}
function getElementTop(element) {
let actualTop = element.offsetTop;
let current = element.offsetParent;
while (current !== null) {
actualTop += current.offsetTop;
current = current.offsetParent;
}
return actualTop;
}
// 方法一: 迭代计算
function getElementAbsoluteByIter(element) {
return {
absoluteTop: getElementTop(element),
absoluteLeft: getElementLeft(element)
}
}
// 方法二: 借助新的API-getBoundingClientRect
function getElementAbsolute(element) {
const { top, left } = getBoundingClientRect(element)
const scrollTop = element.scrollTop
const scrollLeft = element.scrollLeft
return {
absoluteTop: top + scrollTop,
absoluteLeft: left + scrollLeft
};
}
如何获取网页的相对位置:
可以使用getBoundingClientRect直接获取当前元素的相对位置
# 事件目标元素尺寸 Event
Event 代表事件的对象,包含了事件的具体信息。此处使用event代表事件对象参数
event.pageX相对整个页面,以页面左上角为坐标原点到事件所在点的水平距离(IE8以上)event.pageY相对整个页面,以页面左上角为坐标原点到事件所在点的垂直距离(IE8以上)event.clientX相对可视区域,以可视区域左上角为坐标原点到事件所在点的水平距离event.clientY相对可视区域,以可视区域左上角为坐标原点到事件所在点的垂直距离event.screenX相对电脑屏幕,以屏幕左上角为坐标原点到事件所在点的水平距离event.screenY相对电脑屏幕,以屏幕左上角为坐标原点到事件所在点的垂直距离event.offsetX相对于自身,以自身的padding左上角为坐标原点到事件所在点的水平距离event.offsetY相对于自身,以自身的padding左上角为坐标原点到事件所在点的水平距离
# 根元素 Document
假如获取整个文档的尺寸, 究竟是使用document.documentElement还是document.body呢?
这就不得不提到doctype的概念了, doctype是document type的缩写, 用于告诉浏览器当前文档的类型, 以便浏览器能够正确的渲染页面
在JS中可以使用document.compatMode来获取当前文档的doctype类型, 该属性有两个值
BackCompat表示无doctype声明, 浏览器使用怪异模式渲染页面, 此时使用document.body获取宽高CSS1Compat表示有doctype声明, 浏览器使用标准模式渲染页面, 此时使用document.documentElement获取宽高
需要注意
safari比较特别,有自己获取scrollTop的函数window.pageYOffset- 火狐等等相对标准些的浏览器就省心多了,直接用
document.documentElement.scrollTop
其实, document.body.scrollTop与document.documentElement.scrollTop两者有个特点,就是同时只会有一个值生效
比如document.body.scrollTop能取到值的时候,document.documentElement.scrollTop就会始终为0;反之亦然
如果要得到网页的真正的scrollTop值
// 方法一
const scrollTop = document.body.scrollTop
+ document.documentElement.scrollTop;
const scrollLeft = document.body.scrollLeft
+ document.documentElement.scrollLeft;
// 方法二
const scrollLeft = Math.max(
document.documentElement.scrollLeft,
document.body.scrollLeft
);
const scrollTop = Math.max(
document.documentElement.scrollTop,
document.body.scrollTop
);
// 方法三
const scrollTop = document.documentElement.scrollTop
|| window.pageYOffset
|| document.body.scrollTop
|| 0;
# HTMLCollection、NodeList
上述两个属性都能获取元素的节点集合, 但是他们有一些需要注意的差异性
# NodeList
一般而言,NodeList 是一个静态集合,也就意味着随后对文档对象模型的任何改动都不会影响集合的内容。比如 document.querySelectorAll 就会返回一个静态 NodeList
特殊情况
在一些情况下,NodeList 是一个实时集合,也就是说,如果文档中的节点树发生变化,NodeList 也会随之变化。例如,Node.childNodes 是实时的:
# HTMLCollection
DOM 中的 HTMLCollection 是即时更新的(live);当其所包含的文档结构发生改变时,它会自动更新。因此,最好是创建副本(例如,使用 Array.from)后再迭代这个数组以添加、移动或删除 DOM 节点
# 差异性
NodeList是一个静态集合,其不受DOM树元素变化的影响;相当于是DOM树快照,节点数量和类型的快照,就是对节点增删,NodeList感觉不到。但是对节点内部内容修改,是可以感觉到的,比如修改innerHTMLHTMLCollection是动态绑定的,是一个的动态集合,DOM树发生变化,HTMLCollection也会随之变化,节点的增删是敏感的只有
NodeList对象有包含属性节点和文本节点HTMLCollection元素可以通过name,id或index索引来获取。NodeList只能通过index索引来获取HTMLCollection和NodeList本身无法使用数组的方法:pop、push或join等。除非你把他转为一个数组
← WebWorker 实践 前端转换小结 →