# 前端转换小结
本文盘点前端开发中常用的各种转换场景
# Base64与字符串
base64其实是一种编码转换方式, 将ASCII字符转换成普通文本, 是网络上最常见的用于传输 8Bit 字节代码的编码方式之一。
base64由字母a-z、A-Z、0-9以及+和/, 再加上作为垫字的=, 一共 65 字符组成一个基本字符集, 其他所有字符都可以根据一定规则, 转换成该字符集中的字符。
例如:
abcde => YWJjZGU= ABCDE => QUJDREU=
# 转换API
此处只罗列了浏览器下和Node环境下如何进行Base64的转换
# 浏览器
最新的浏览器自带了两个方法用于base64的编码和解码, 分别是atob和btoa
- atob:将
base64转成8bit字节码 - btoa:将
8bit字节码转成base64
对于旧版浏览器, 可以使用js-base64 (opens new window)
# Node
目前node中还不支持使用atob和btoa,但是可以通过Buffer来实现, 参考文档 (opens new window)
if (typeof btoa === 'undefined') {
global.btoa = function (str) {
return Buffer.from(str).toString('base64')
}
}
if (typeof atob === 'undefined') {
global.atob = function (b64Encoded) {
return Buffer.frome(b64Encoded, 'base64').toString()
}
}
# 直接转换
base64 编码方式对于中文是不适用的, 因为中文对应多个字节, 因此可以先使用encodeURIComponent编码后再进行base64编码
笔者在github发现了相关转换的库 (opens new window), 收录在此处
# 编码
- 每三个字节作为一组,每个字节 8bit, 一共是 24 个二进制位。
'ABCD'
[('ABC', 'D')] // 每三字节做一组
[('01000001 01000010 01000011', '01000100')] // 转成8bit
- 将每组的 24 个二进制位再细分为四组,每组有 6 个二进制位, 此时为二维数组。
[
['010000', '010100', '001001', '000011'],
['010001', '00']
]
特殊情况
二个字节的情况:将这二个字节的一共 16 个二进制位, 按照上面的规则, 转成三组, 那么最后一项只有 4 位,则在后面加两个 0, 补够 6 位, 并在第三步对应位置加上垫字符
=。一个字节的情况:将这一个字节的 8 个二进制位,按照上面的规则转成二组, 那么最后一项只有 2 位, 则在后面加上四个 0, 并在第三步对应位置加上两个垫字符
=。简单说就是, 缺多少位就在后面补多少个 0, 直到满 6 位。
[ ['010000', '010100', '001001', '000011'], ['010001', '000000'] ]
在每组前面加两个 00,扩展成 32 个二进制位,即四个字节。
将每组对应的二进制转成十进制, 在
base64char字符集中找到对应的字符。
[
['Q', 'U', 'J', 'D'],
['R', 'A']
]
特殊情况
每一组都最终都应该转成四个字符
如果不足四个字符, 说明明文中并不足 3 字节, 因此需要补上垫字符
=, 补够四个字符
[ ['Q', 'U', 'J', 'D'], ['R', 'A', '=', '='] ]
- 将最后的结果连接成字符串, 则为最终编码结果。
'ABCD' > 'QUJDRA=='
根据编码方式来看, 每 3 个字节将会被编码成四个字符, 如果不足 3 个字节, 则补上垫字符=, 缺几个就补几个。
btoa('A') // "QQ=="
btoa('AB') // "QUI="
btoa('ABC') // "QUJD"
btoa('ABCD') // "QUJDRA=="
# 解码
解码步骤就是跟编码步骤反过来
每四个字节分为一组
将每组的中除了垫字符
=外的字符, 在base64char字符集中找到所在下标将十进制下标转成二进制, 如果不够 6 位(一定不会超过 6 位), 则在前面补
0
特殊情况
如果遇到垫字符
=, 说明其明文不足 3 字节, 则根据垫字符=的数量, 在该组最后一项中去掉对应个数的0一个垫字符, 则去掉两个
0两个垫字符, 则去掉四个
0
将每组中的二进制字符串连接,此时字符串长度一定是 8 的倍数,然后每 8 位分割成一个字节
通过
String.fromCharCode将二进制转成字符, 然后拼接将各个字符连接, 为最终解码结果
# 文件对象转换
# 文件转DataURL
DataURL 由四个部分组成, 前缀(data:)、指示数据类型的 MIME 类型、如果非文本则为可选的 base64 标记、数据本身
定义
data:[<mediatype>][;base64],<data>
例如: data:image/png;base64,iVBORw0KGgoAAAANSUh...
function fileToDataURL(file) {
const reader = new FileReader()
reader.readAsDataURL(file)
reader.onload = function (e) {
// console.log('dataURL->', reader.result)
const dataURL = reader.result
}
}
上述函数中使用了FileReader构造函数, 返回的实例包含了几读取器, 他们的参数均为被读取的 Blob 或 File 对象
- instance.readAsArrayBuffer(blob)
- instance.readAsBinaryString(blob) - 非标准API
- instance.readAsDataURL(blob)
- instance.readAsText(blob[, encoding])
# DataURL转Blob
Blob() 构造函数返回一个新的 Blob 对象。blob 的内容由参数数组中给出的值的串联组成
Blob构造函数语法
const aBlob = new Blob( array, options )
array 是一个由
ArrayBuffer,ArrayBufferView,Blob,DOMString等对象构成的Array,或者其他类似对象的混合体,它将会被放进 Blob。DOMStrings 会被编码为 UTF-8。options 是一个可选的BlobPropertyBag字典,它可能会指定如下两个属性:
- type,默认值为 "",它代表了将会被放入到 blob 中的数组内容的 MIME 类型。
- endings,默认值为"transparent",用于指定包含行结束符\n的字符串如何被写入。它是以下两个值中的一个:"native",代表行结束符会被更改为适合宿主操作系统文件系统的换行符,或者 "transparent",代表会保持 blob 中保存的结束符不变 非标准
function dataURLToBlob(dataURL) {
const arr = dataURL.split(','),
mime = arr[0].match(/:(.*?);/)[1],
bstr = atob(arr[1]),
u8arr = new Uint8Array(n);
n = bstr.length;
while(n --) {
u8arr[n] = bstr.charCodeAt(n)
}
// console.log('blob->', new Blob([u8arr], {type: mime}))
return new Blob([u8arr], {type: mime})
}
# 文件转BlobURL
URL.createObjectURL() 静态方法会创建一个 DOMString,其中包含一个表示参数中给出的对象的 URL。这个 URL 的生命周期和创建它的窗口中的 document 绑定。这个新的 URL 对象表示指定的 File 对象或 Blob 对象
语法
const objectURL = URL.createObjectURL(object)
object 用于创建 URL 的
File 对象、Blob 对象或者MediaSource 对象返回值 一个DOMString包含了一个对象 URL,该 URL 可用于指定源 object的内容
function fileToblobURL(file) {
return URL.createObjectURL(file)
}
# BlobURL转文件
如果源文件是任意文件, 要将BlobURL还原为Blob源文件, 可以使用fetch或者xhr
/* 将blobURL转换为源文件 */
// 方式一: 使用fetch
async function blobURLToBlobByFetch(blobURL) {
const blob = await fetch(blobURL).then(r => r.blob())
return blob
}
// 方式二: 使用xhr
function blobURLToBlobByXhr(blobURL){
return new Promise((resolve)=>{
const xhr = new XMLHttpRequest();
// 设置 responseType 为 "blob"
xhr.responseType = "blob"
// 发送 GET 请求以获取 Blob 数据
xhr.open("GET", blobURL)
xhr.onload = function() {
if (xhr.status === 200) {
// 这里的 xhr.response 就是还原后的 Blob 对象
resolve(xhr.response)
}
};
xhr.send()
})
}
如果源文件是图片, 可以使用canvas来进行转换
function blobURLToFile(blobURL) {
return new Promise((resolve) => {
const canvas = document.createElement('canvas')
const ctx = canvas.getContext('2d')
const image = new Image()
image.src = blobURL
image.onload = () => {
ctx.drawImage(image, 0, 0, canvas.width, canvas.height)
canvas.toBlob((blob)=>{
resolve(new File([blob],{ type:'image/png' }))
}, 'image/png', 1.0)
}
})
}
上述函数使用了canvas来作为中间手段, canvasAPI中, 涉及文件转换的几个API如下:
canvas.toBlob(callback, type, quality)
callback 回调函数,可获得一个单独的 Blob 对象参数。如果图像未被成功创建,可能会获得 null 值。
type 可选 DOMString 类型,指定图片格式,默认格式(未指定或不支持)为 image/png。
quality 可选 Number 类型,值在 0 与 1 之间,当请求图片格式为 image/jpeg 或者 image/webp 时用来指定图片展示质量。如果这个参数的值不在指定类型与范围之内,则使用默认值,其余参数将被忽略。
canvas.toDataURL(type, encoderOptions)
type 可选 图片格式,默认为 image/png
encoderOptions 可选 在指定图片格式为 image/jpeg 或 image/webp 的情况下,可以从 0 到 1 的区间内选择图片的质量。如果超出取值范围,将会使用默认值 0.92。其他参数会被忽略。
# File转Blob对象
File() 构造器创建新的 File 对象实例, File 对象是特殊类型的 Blob,且可以用在任意的 Blob 类型的 context 中。比如说, FileReader, URL.createObjectURL(), createImageBitmap() (en-US), 及 XMLHttpRequest.send() 都能处理 Blob 和 File
File构造函数语法
const myFile = new File(bits, name[, options])
bits 一个包含ArrayBuffer,ArrayBufferView,Blob,或者 DOMString 对象的 Array — 或者任何这些对象的组合。这是 UTF-8 编码的文件内容。
name USVString,表示文件名称,或者文件路径。
options 可选 选项对象,包含文件的可选属性。可用的选项如下:
- type: DOMString,表示将要放到文件中的内容的 MIME 类型。默认值为 "" 。
- lastModified: 数值,表示文件最后修改时间的 Unix 时间戳(毫秒)。默认值为 Date.now()。
// 方法一 通过FileReader
async function fileToBlob(file) {
const arraybuffer = await new Promise((resolve, reject) => {
const reader = new FileReader()
reader.onload = () => {
resolve(reader.result)
}
reader.onerror = reject
reader.readAsArrayBuffer(file)
})
const blob = new Blob([arraybuffer], { type: file.type })
// console.log('fileToBlob:', blob);
}
// 方法二 通过fetch
async function fileToBlobByFetch(file){
const url = URL.createObjectURL(file)
const blob = await fetch(url).then(r=> r.blob())
// console.log('fileToBlobByFetch:', blob);
return blob
}
// 方法三 使用构造函数
function fileToBlob(file){
return new Blob([file], { type: file.type })
}
# Blob转File对象
直接使用构造函数即可
function fileToBlob(blob, filename){
return new File([blob], filename, { type: blob.type })
}
# 隐式转换
# 加法运算的隐式转换
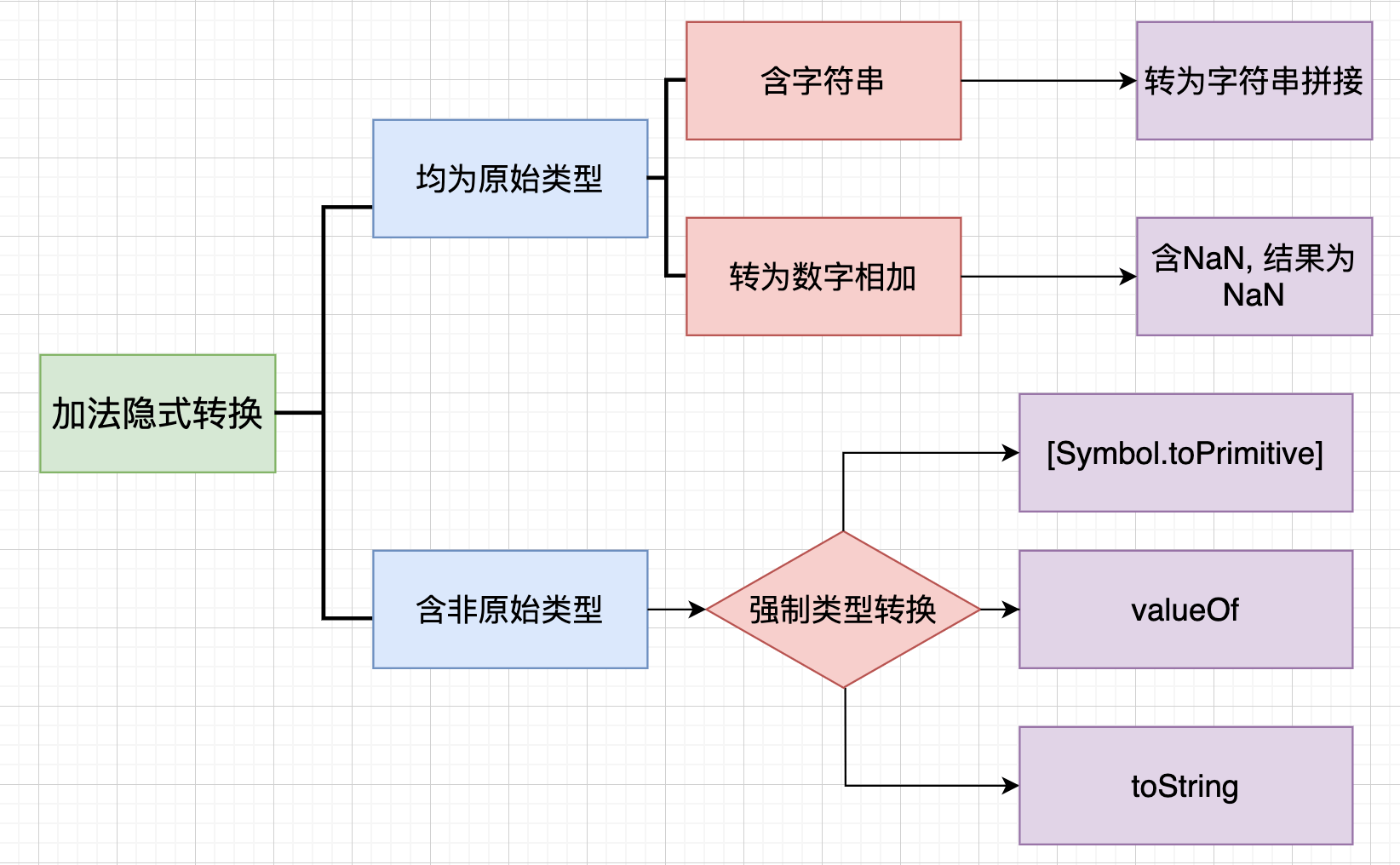
常见基本类型转为数字规则:
- null 转为数字 0
- undefined 转为数字 NaN
- true 转为数字 1
- false 转为数字 0
- Symbol() 无法转为数字, 会报错
- 两个BigInt数字相加结果是BigInt, BigInt与普通数字相加会报错
常见引用类型强制转换为基本类型规则:
- 先检查是否有
[Symbol.toPrimitive]方法, 如果有则调用, 返回结果不是原始类型就报错。 如果没有这个方法, 则进入下一步 - Date对象, 先调用
toString方法, 仍无法转成原始类型, 则最后调用valueOf方法 - 其他对象, 先调用
valueOf方法, 仍无法转成原始类型, 再调用toString方法
# 双等运算的隐式转换
等号运算的通用规则如下:
- 两端类型相同, 比较值
- 两端存在
NaN, 返回false undefined和null只有与自身比较, 或者相互比较时, 才会返回true- 两端都是原始类型, 转换成数字比较
- 一端是原始类型, 一端是对象类型, 把对象类型转换成原始类型后, 再进行原始值比较(上一步)
这里的隐式转换与加法的隐式转换规则一致, 即先检查[Symbol.toPrimitive], 后调用toString或valueOf
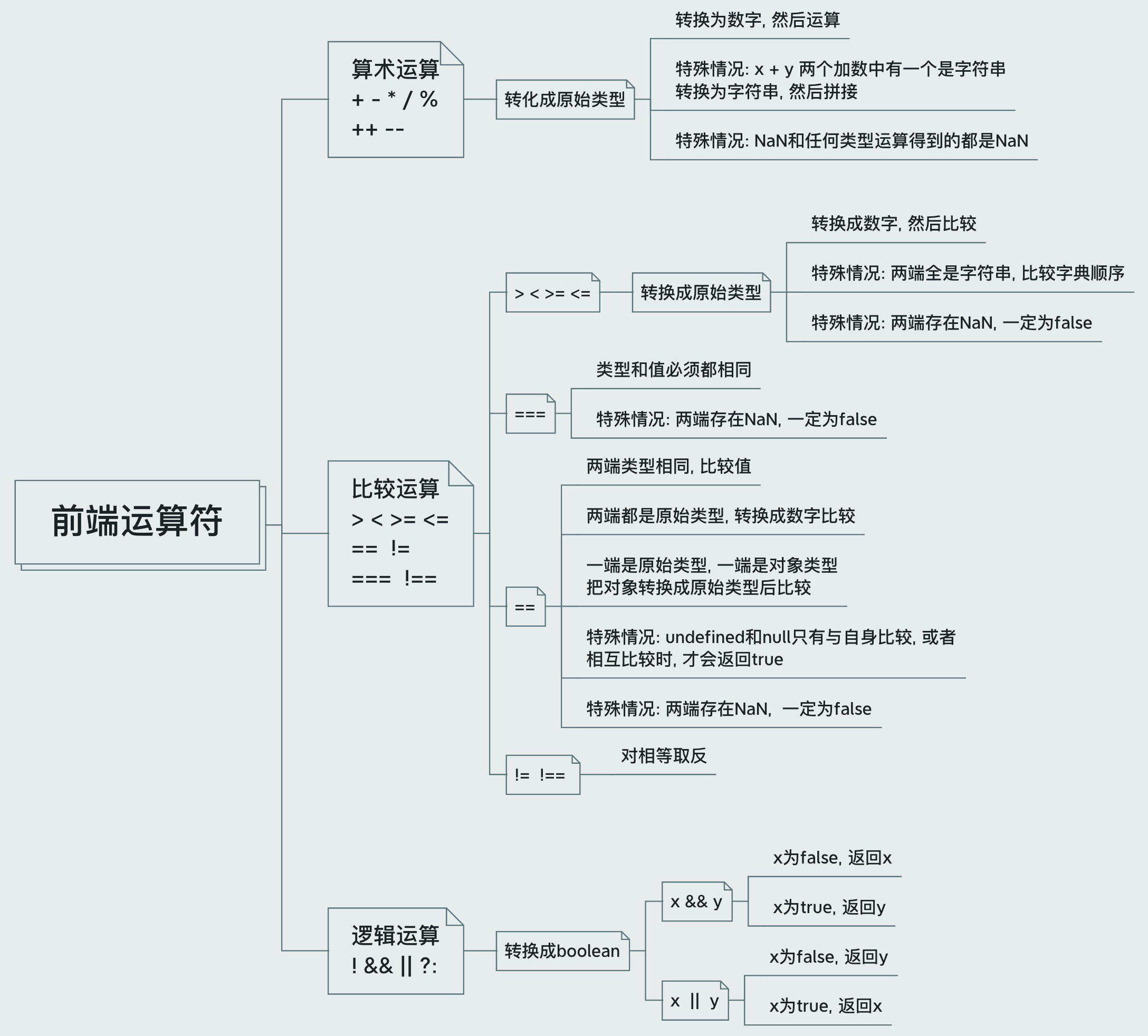
# 前端运算的隐式转换
此处通过思维导图来总结一下, 前端的运算符
# 一些特殊情况
涉及到对象的隐式转换中, 书写顺序不同可能会带来截然不同的结果
注意
这些输出结果可能在不同的 JavaScript 环境中有所不同。在某些环境中,例如 Node.js,您可能会看到与我在这里提供的输出结果不同的结果。
{} + 2与2 + {}
前者对象字面量的大括号在这里被解释为代码块,输出数字 2。后者会进行隐式转换,输出字符串 2[object Object]
[] + 2与2 + []
两者情况一致, 都会经过隐式转换, 输出 字符串 [object Object]2和字符串 2[object Object]
{ name: 'abc' } + 2与2 + { name: 'abc' }
跟第一种情况一致, 因此输出分别为数字 2 和字符串 2[object Object]
从上面的规律来看, 对象与数字相加/减, 如果对象写在前面, 会被解析为代码块, 导致输出异常。这种情况下可以主动将前面的对象加上括号进行包装,({}) + 2 来解决这种行为不一致的现象
# 进制转换
# 进制表示法
使用字面量(literal)直接表示一个数值时,JavaScript 对整数提供四种进制的表示方法
- 十进制:没有
前导0的数值 - 八进制:前缀
0o或0O的数值,或者有前导0的数值,但前者兼容性更好 - 十六进制:有前缀
0x或0X的数值 - 二进制:有前缀
0b或0B的数值
# 其他进制转十进制
- parseInt(str, radix): 根据 radix 可以将字符串转成十进制
// n进制转十进制
parseInt('1000', 2) // 8
parseInt('1000', 16) // 4096
# 数字转任意进制
- number.toString(radix): 将
number转成其他进制
(10).toString(2) // 1010
(0xff).toString(2) // 11111111, 16进制转2进制
(0b1100).toString(8) // 14, 2进制转8进制
一些特殊情况
数字使用toString进行进制转换的过程中, 书写方式的不同, 行为也是不一样的
2.toString('2') // 报错, 由于`.`的存在, 会被解析为浮点数, 而不认为是函数调用, 从而报错
// 因此我们可以使用包装的数字类型或者使用双点
(2).toString('2') // 正常输出 "10"
2..toString('2') // 通过双点来避免错误的解析, 从而正常输出 "10"